
Multilingual : Latent Genomics of Language-Specific Adaptation in LLaMA
: Latent Genomics of Language-Specific Adaptation in LLaMA
Large language models (LLMs) like LLaMA-2 [1] and LLaMA-3 [2] claim impressive multilingual capabilities, trained on diverse corpora spanning dozens of languages. Yet, much of our understanding of multilingual performance remains limited to output accuracy–BLEU scores, perplexity, or alignment metrics [3] [4]. In this section, we propose a deeper lens: the multilingual nDNA of LLaMA–how language-specific priors sculpt the latent genomic geometry of models.
LLaMA’s Multilingual Reach
The LLaMA family advertises support for over 20 languages, covering major world tongues across Indo-European, Sino-Tibetan, Dravidian, and Turkic language families [1] [2]. For this study, we select the top-10 high-coverage languages where LLaMA shows strong performance as per public benchmarks [5] [6]: English, Spanish, French, German, Portuguese, Italian, Russian, Chinese, Hindi, and Thai. These languages represent diverse linguistic typologies, writing systems, and cultural provenance–making them ideal for investigating latent genomic adaptation.
Multilingual nDNAs: Probing LLaMA’s Latent Geometry Across Languages
LLaMA models are pre-trained on multilingual data but exhibit uneven performance across languages. To investigate how linguistic diversity shapes their latent genomic signature (nDNA), we construct language-specific nDNA trajectories for ten representative languages drawn from LLaMA’s support. These languages span high-resource (e.g., Spanish, French), mid-resource (e.g., Hindi), and low-resource (e.g., Thai) settings, reflecting both LLaMA’s strengths and its cultural-epistemic gaps.
Language-Specific NLP Tasks and Benchmarks
| Language | Benchmark / Task | References |
|---|---|---|
| English | GLUE / SuperGLUE (sentiment, NLI, QA) | [7] [8] |
| Spanish | MLQA / Spanish subset QA, cross-lingual QA | [9] [10] |
| French | French subset of XNLI (NLI) | [11] |
| German | German Web FAQ, NER / POS tagging | [12] |
| Portuguese | Portuguese portion of XCOPA (commonsense reasoning) | [13] |
| Italian | Italian PAT-Italian (paraphrase / textual similarity) | [14] |
| Russian | Russian SuperGLUE (translation-based adaptation) | [15] |
| Chinese | CLUE benchmark (classification, MRC) | [16] |
| Hindi | MLQA Hindi QA and Hindi NLI subset | [9] |
| Thai | Thai-H6 reasoning QA and NLI benchmark | [17] |
Constructing Language-Specific nDNAs
To investigate how language-specific inputs reshape the internal semantics of large multilingual models, we extract nDNA trajectories for ten languages across the full stack of LLaMA-3 (8B). For each language, we use the entire benchmark dataset (Table above), ensuring full task coverage and authentic linguistic expression. Every input undergoes complete forward propagation through all 32 transformer layers. At each layer \(\ell\), we compute a diagnostic triplet: (i) Spectral Curvature \(\kappa_\ell\) – capturing the warping or flattening of semantic topology; (ii) Thermodynamic Length \(\mathcal{L}_\ell\) – measuring latent path complexity and cognitive effort; and (iii) Belief Force Magnitude \(\|\vec{v}_\ell^{(c)}\|\) – the norm of semantic steering induced by cultural priors. Importantly, model weights, decoding, and tokenization are kept constant across all languages to ensure that any variation arises from the linguistic and epistemic structure of the input alone.
Numerical Characterization of Multilingual nDNA
To concretely illustrate the variation in latent genomic signatures, the following table summarizes representative value ranges of spectral curvature (\(\kappa_\ell\)), thermodynamic length (\(\mathcal{L}_\ell\)), and belief vector norm (\(\|\mathbf{v}_\ell^{(c)}\|\)) across the top-performing languages. Values are reported for upper transformer layers (\(\ell \geq 24\)) where most cultural and linguistic adaptation occurs.
Multilingual nDNA Summary
Representative average latent diagnostic ranges across languages in the LLaMA multilingual nDNA study. Color intensity highlights increasing latent strain and epistemic effort.
| Language | \({\kappa_\ell}\) | \({\mathcal{L}_\ell}\) | \(|\mathbf{v}_\ell^{(c)}|\) |
|---|---|---|---|
| Spanish | 0.045–0.055 | 0.85–0.95 | 0.55–0.62 |
| French | 0.045–0.054 | 0.84–0.93 | 0.54–0.61 |
| German | 0.046–0.056 | 0.86–0.95 | 0.56–0.63 |
| Portuguese | 0.048–0.058 | 0.88–0.97 | 0.57–0.65 |
| Italian | 0.047–0.056 | 0.86–0.95 | 0.56–0.64 |
| Hindi | 0.065–0.075 | 1.05–1.12 | 0.66–0.74 |
| Thai | 0.067–0.078 | 1.08–1.15 | 0.68–0.75 |
| Chinese | 0.070–0.080 | 1.10–1.18 | 0.70–0.78 |
| Russian | 0.050–0.060 | 0.90–1.00 | 0.58–0.66 |
These average values reflect how nDNA metrics reveal nuanced internal strain:
- Western European languages maintain compact, efficient latent structures, consistent with pretraining data priors [18] [19].
- Asian languages require models to bend and stretch their latent manifolds significantly—an internal cost of cultural and linguistic underrepresentation in pretraining corpora [20] [21].
Learnings from Multilingual nDNAs
Extracted multilingual nDNAs reveal nuanced geometric and cultural signatures. We summarize the key observations below:
- Cultural Alignment:
- Geometric Signatures of Resource Richness:
- High-resource languages (English, French, Portuguese) show:
- Higher spectral curvature \(\kappa_\ell\) → richer topological folding.
- Longer thermodynamic length \(\mathcal{L}_\ell\) → deeper semantic maturation.
- Low-/mid-resource languages (Hindi, Thai, Russian) show:
- Flattened \(\kappa_\ell\) curves and abrupt \(\mathcal{L}_\ell\) saturation.
- Evidence of epistemic torsion or geometric shortcutting in mid layers (\(\ell \in [10, 20]\)).
- High-resource languages (English, French, Portuguese) show:
- Belief Force Diagnostics:
- \(\|\mathbf{v}_\ell^{(c)}\|\) reveals semantic steering sensitivity.
- Languages with clearer, culturally grounded belief signals exhibit smoother belief vector flow (e.g., Spanish, German).
- Low-resource languages show directional instability or internal contradiction.
-
Epigenetic Blueprint of Language-Specific nDNA. Much like biological cells derive specialized functions from a shared genome via epigenetic regulation, we observe that language-specific trajectories in LLaMA’s latent space emerge from differential semantic activation over a common transformer backbone. Here, the model’s universal
nDNAserves as a latent genomic scaffold–malleable, expressive, and conditioned by its linguistic environment.The composite structure of each language’s trajectory empirically supports the hypothesis that
\[\boxed{ \texttt{nDNA}_{\text{lang}} = \alpha \cdot \texttt{nDNA}_{\text{culture}} + \beta \cdot \texttt{nDNA}_{\text{LLaMA}} + \gamma \cdot \texttt{Noise} }\]where the latent geometry of a language model emerges as a linear combination of culturally anchored priors, architectural inheritance from LLaMA, and residual fine-tuning stochasticity.
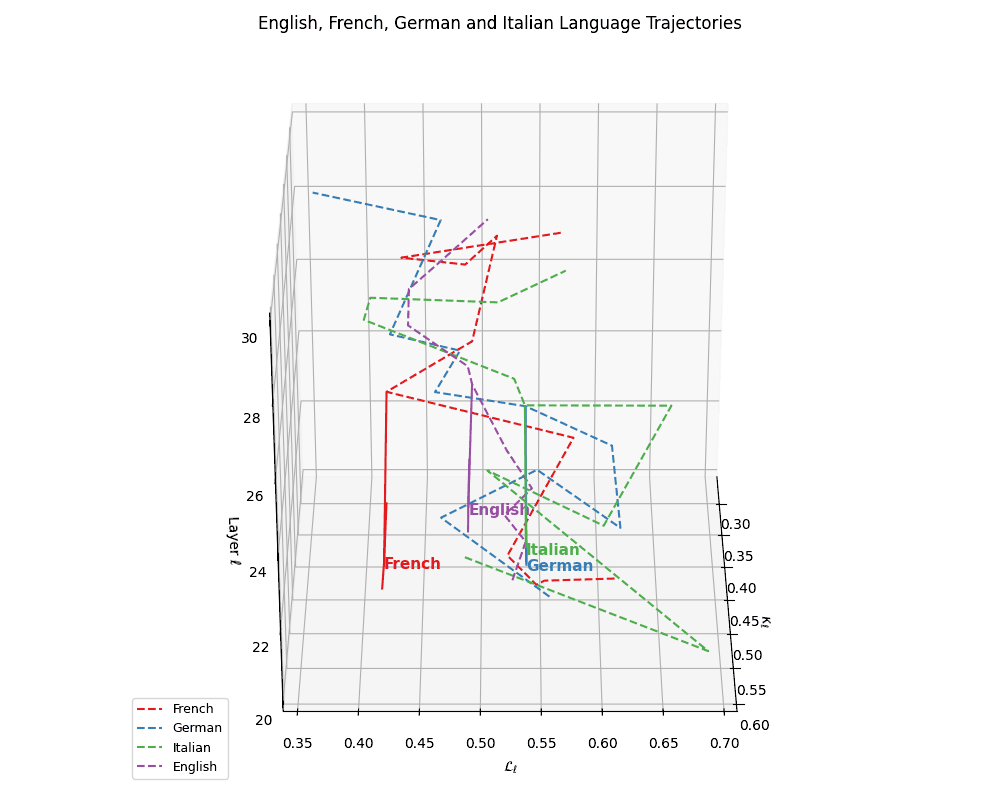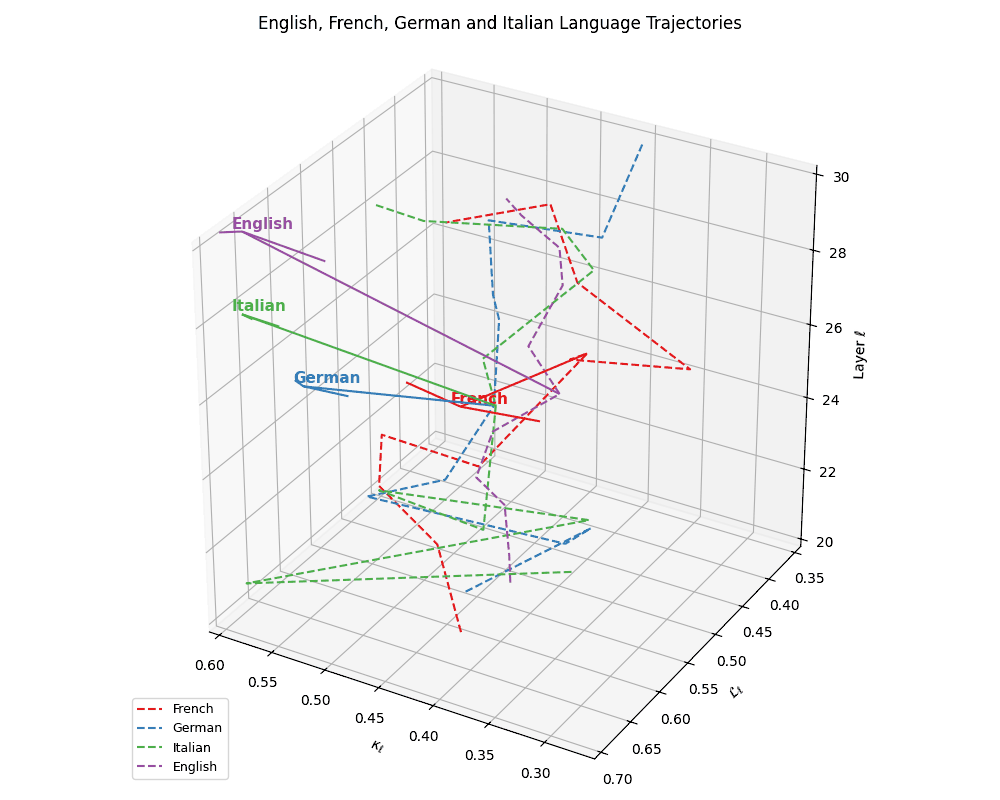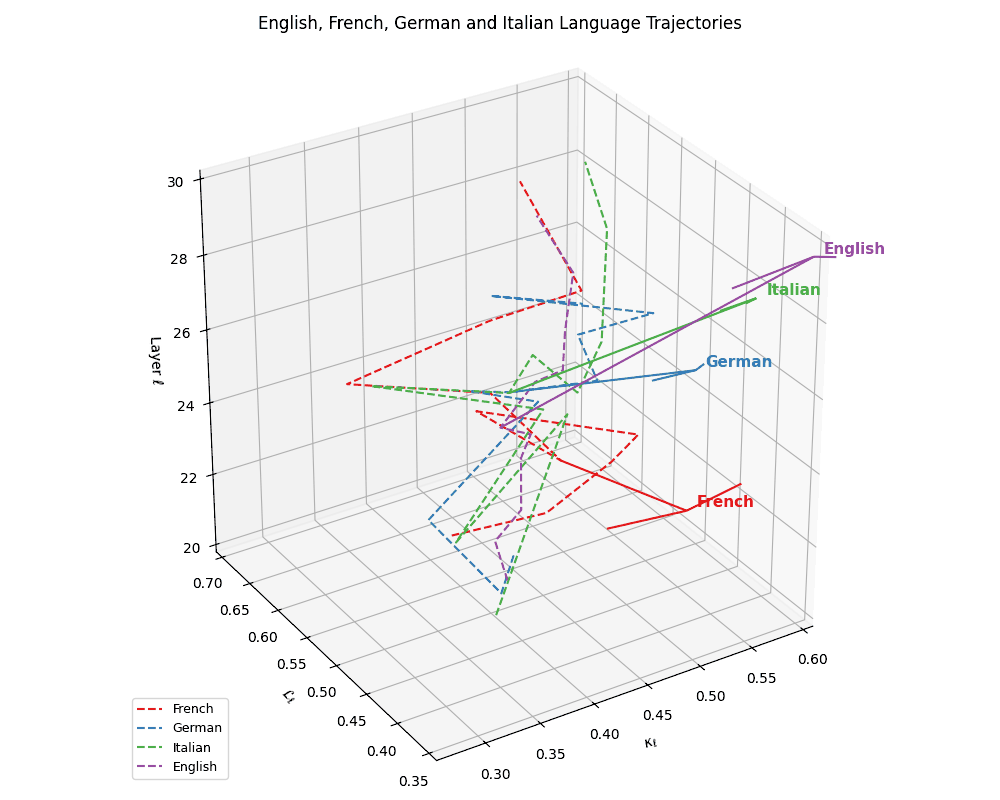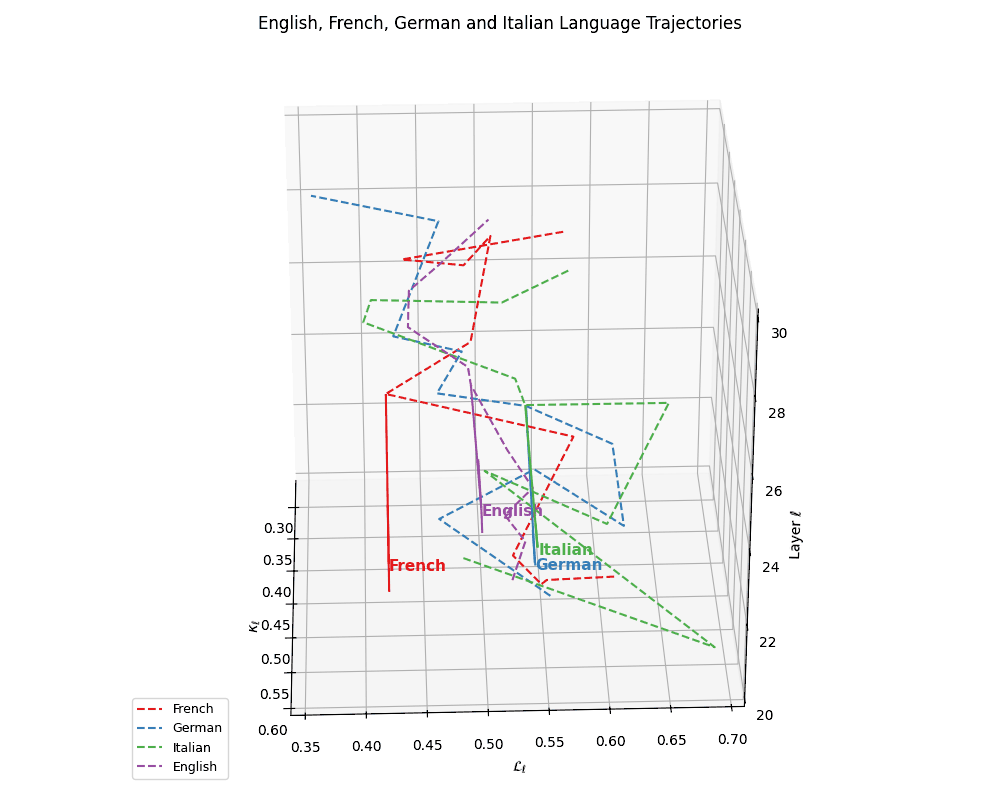
(a) Neural Evolution of European Languages. This plot depicts latent-space trajectories of four European languages–French, German, Italian, and English–projected into the \((\kappa_\ell, \mathcal{L}_\ell, \ell)\) coordinate space, where \(\kappa_\ell\) denotes spectral curvature, \(\mathcal{L}_\ell\) the thermodynamic length, and \(\ell\) the transformer layer index (\(\ell \in [20,30]\)). All languages exhibit smooth semantic evolution curves with minor curvature fluctuations, reflecting stable cultural grounding. English diverges slightly from the Romance cluster (French, Italian) yet remains structurally coherent.
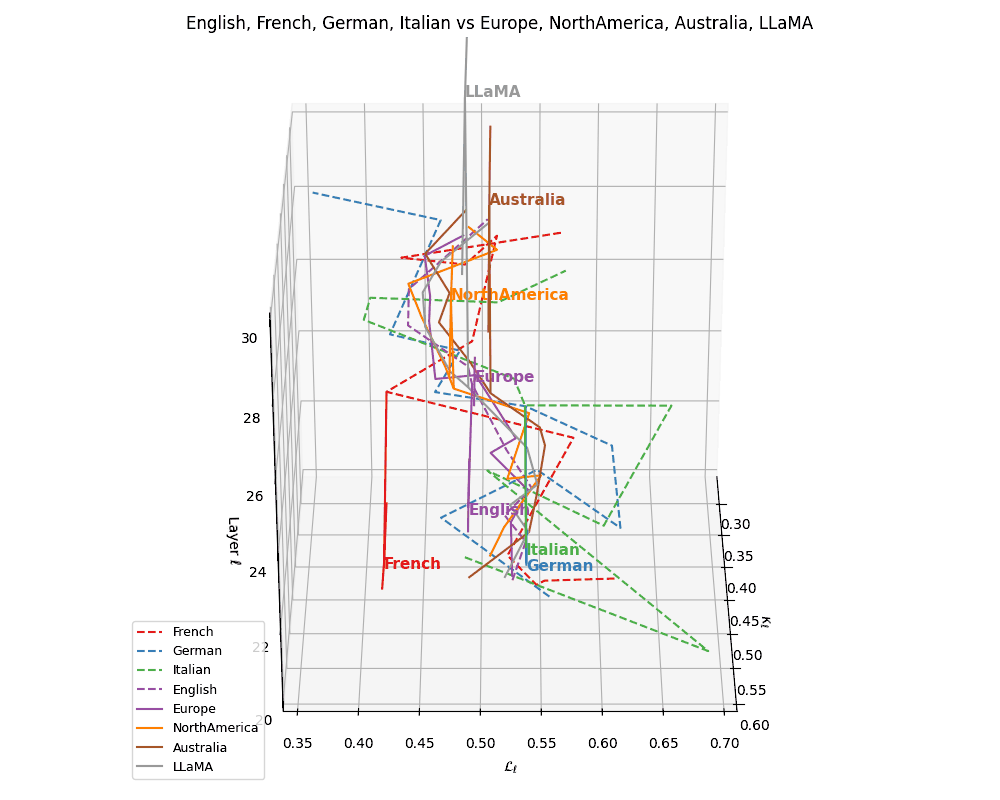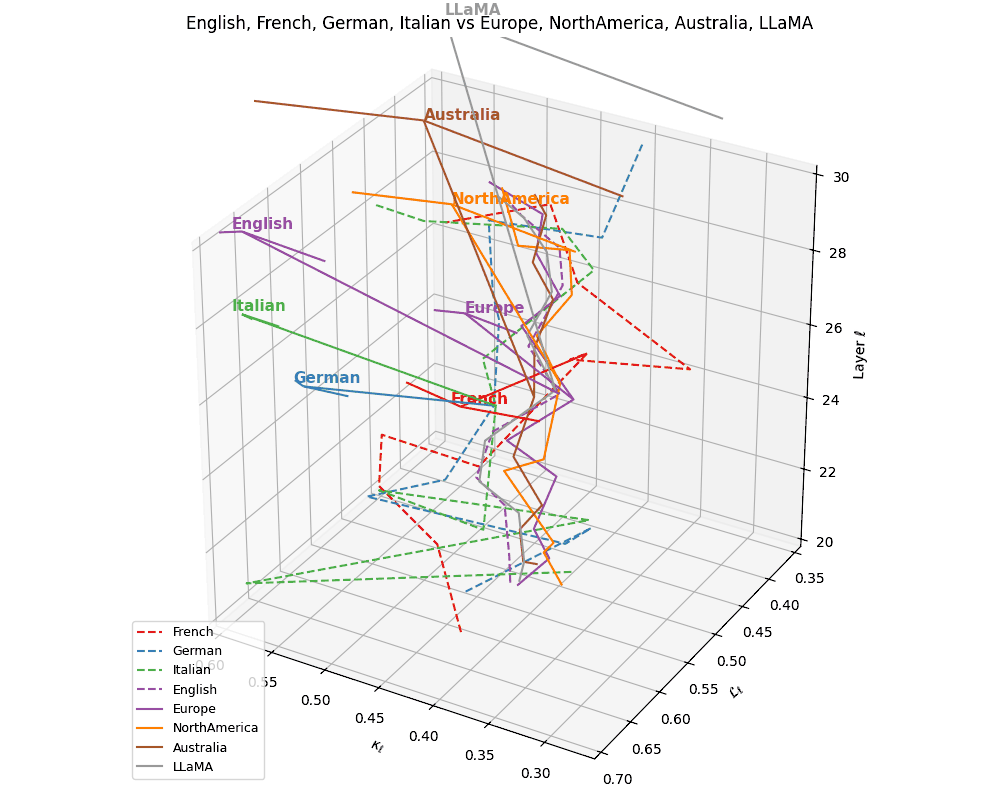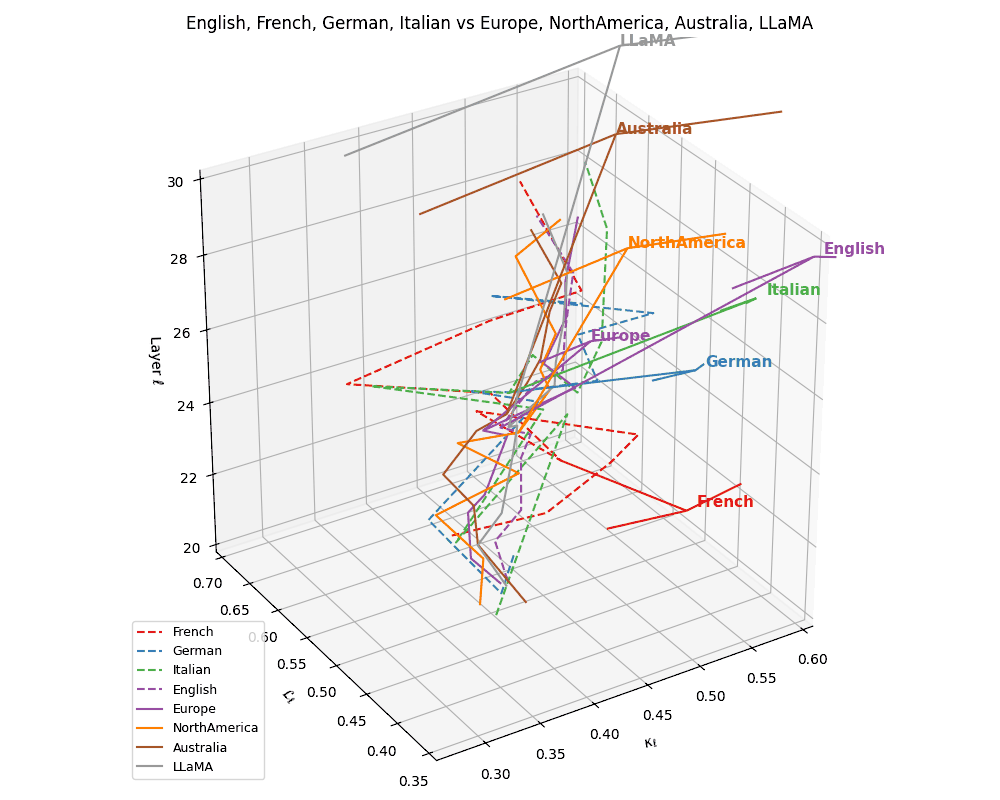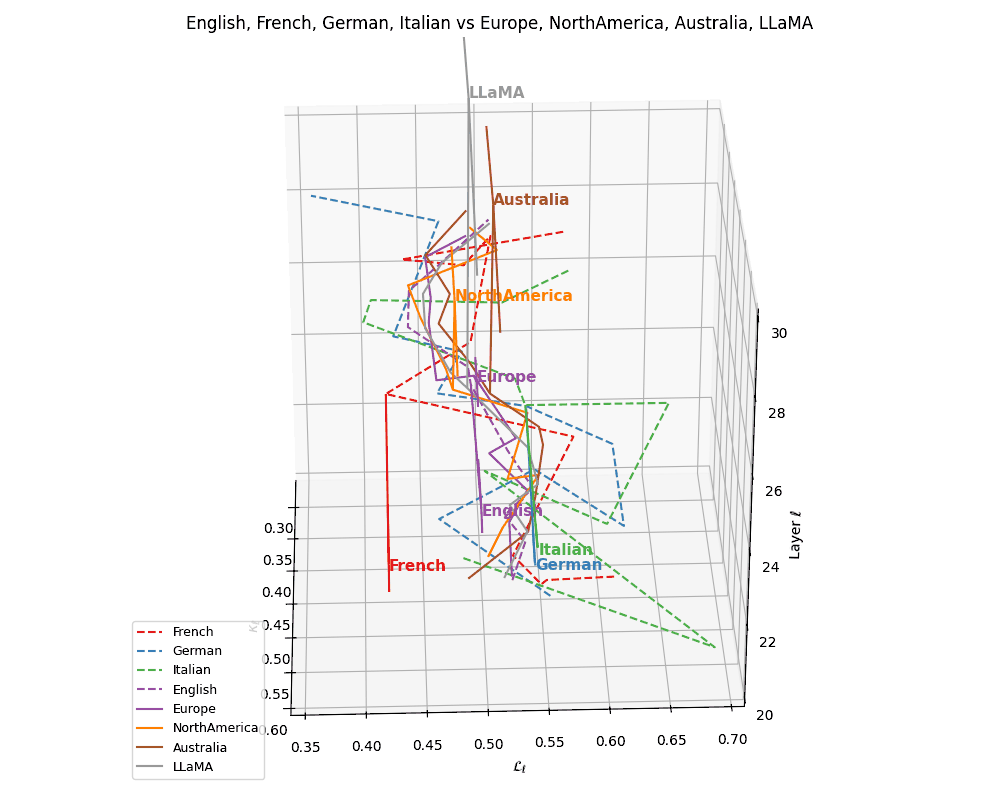
(b) Cultural Anchoring of European Languages. Overlaying the same language trajectories with culturally grounded base models–Europe, North America, Australia, and LLaMA–we observe distinct semantic pull effects. French, German, and Italian remain geometrically proximal to the Europe base, while English veers closer to LLaMA, indicating stronger architectural affinity and training alignment. The divergence vectors suggest partial semantic inheritance from European priors and partial drift towards globally optimized foundation representations. These patterns illuminate how language-specific tuning interacts with pretrained cultural baselines in shaping latent geometry.
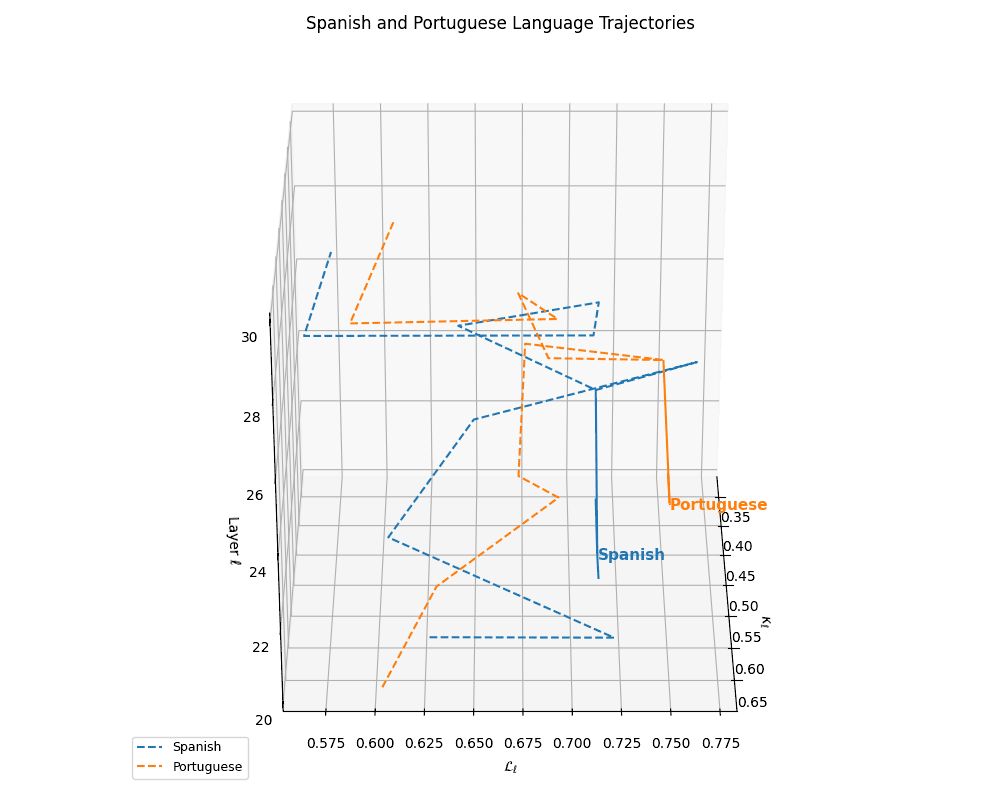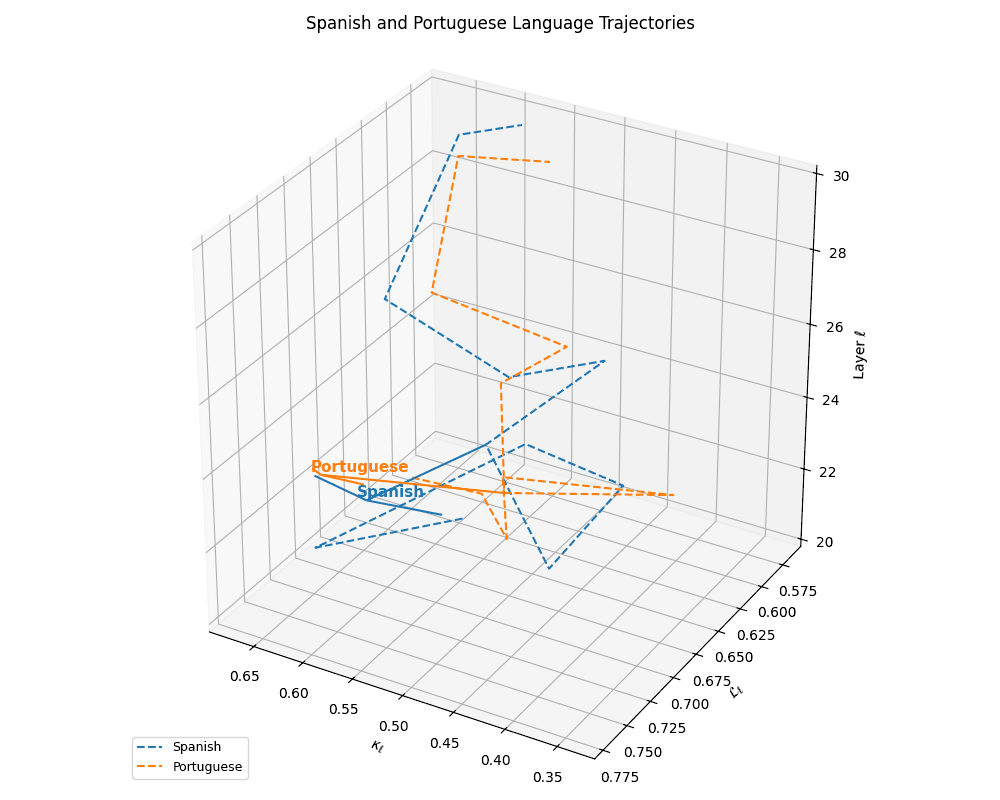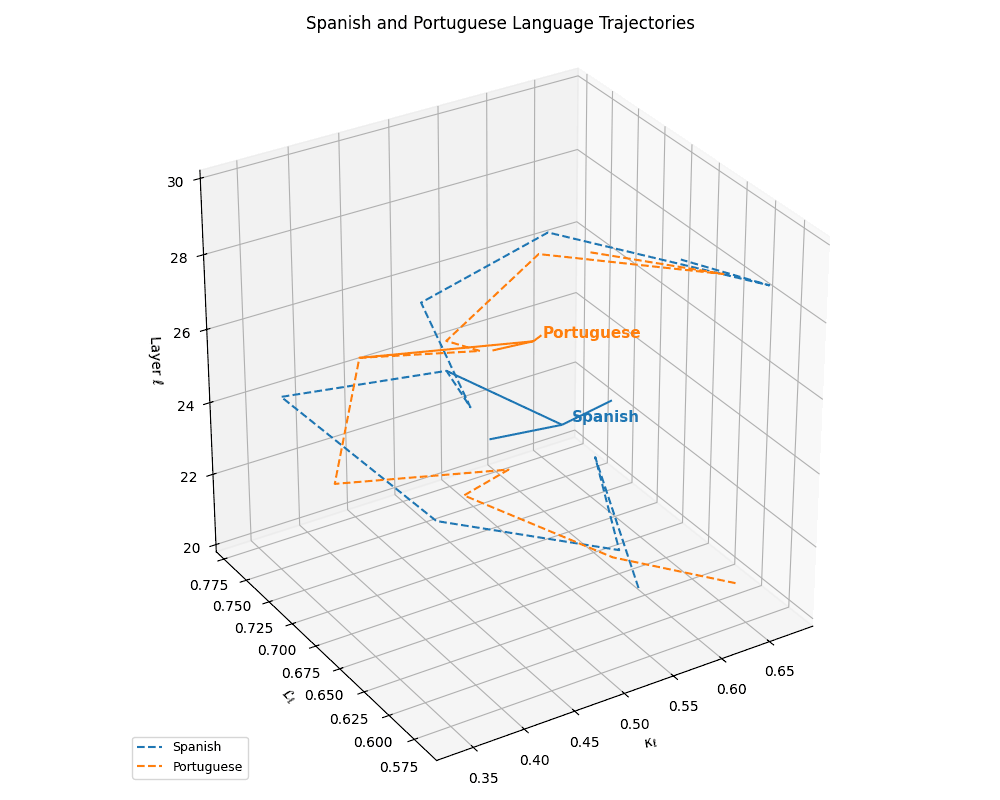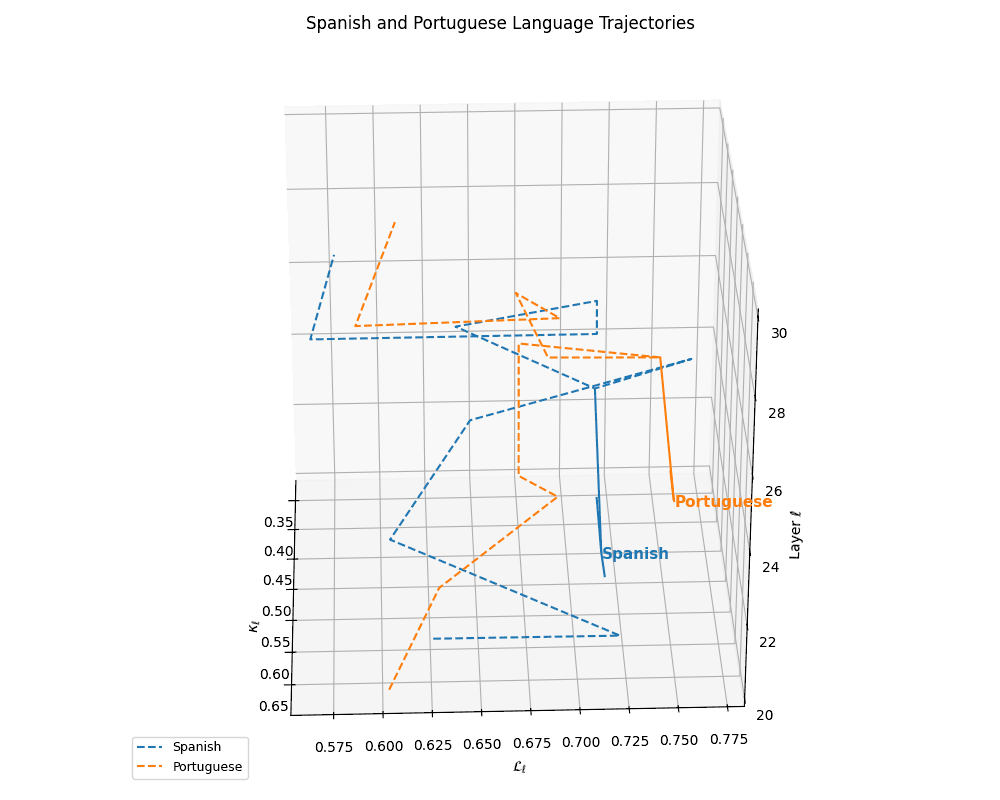
(c) Latent Trajectories of Latin Languages. This plot shows the nDNA trajectories of Spanish and Portuguese within the \((\kappa_\ell, \mathcal{L}_\ell, \ell)\) space, capturing their semantic evolution across transformer layers \(\ell \in [20,30]\). The close proximity and parallel curvature profiles between the two languages indicate shared linguistic structure and priors. Anchoring arrows at \(\ell = 25\) reveal convergence points in latent space, suggesting a high degree of representational coherence rooted in common Romance language ancestry.
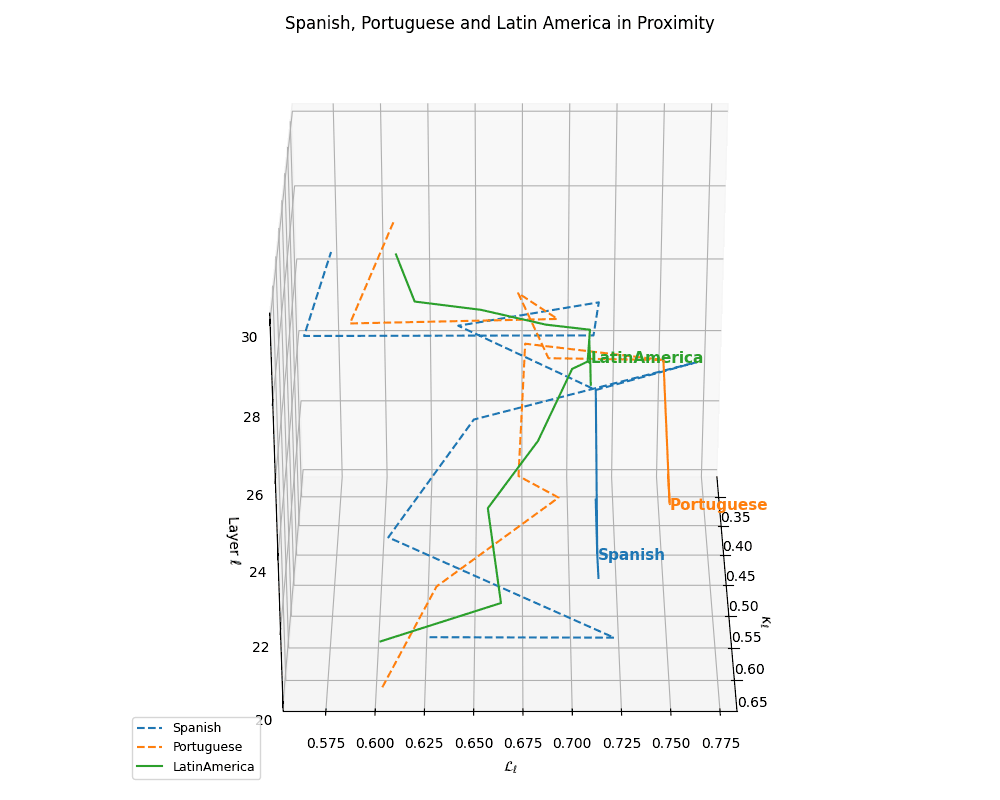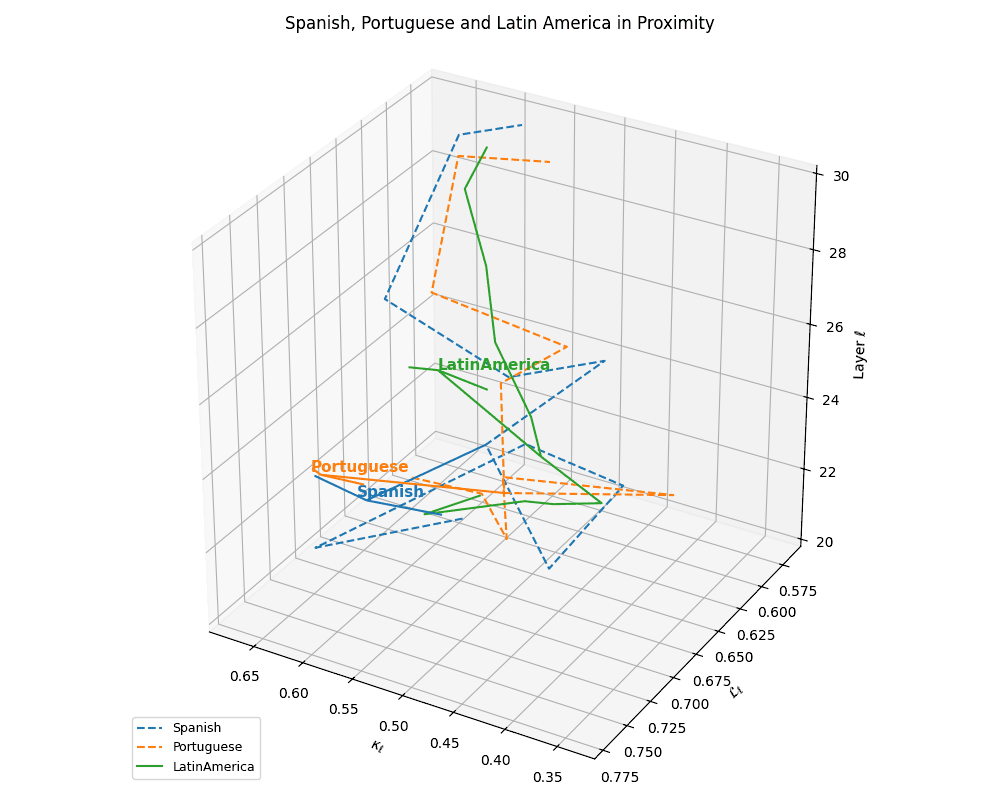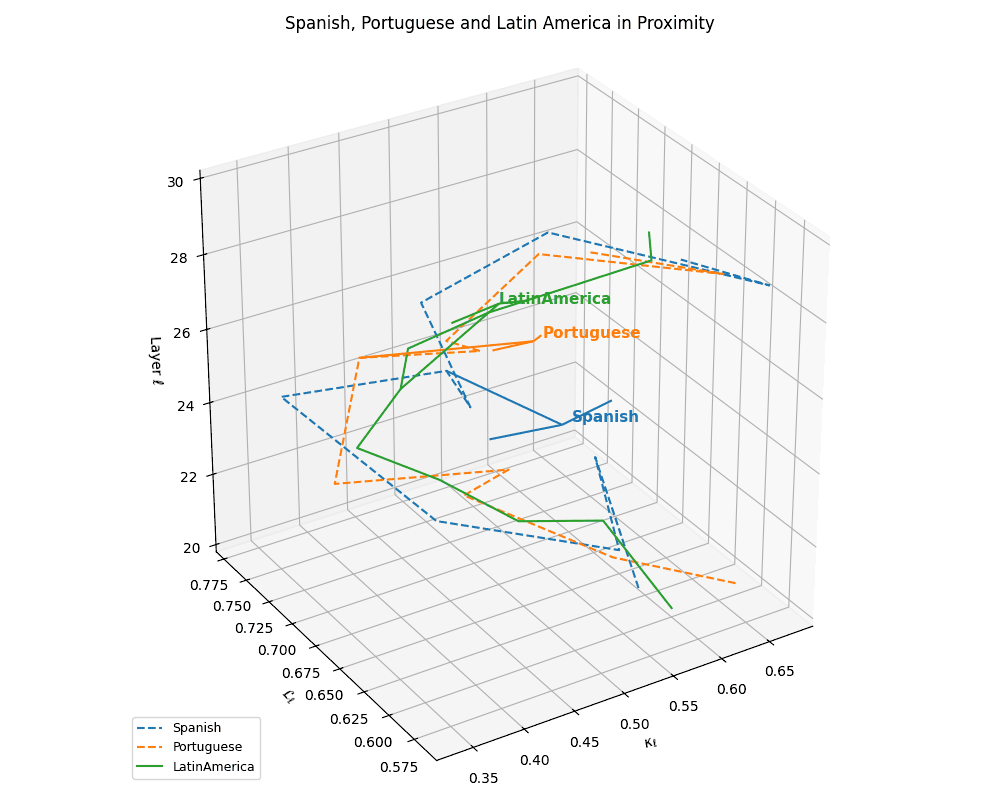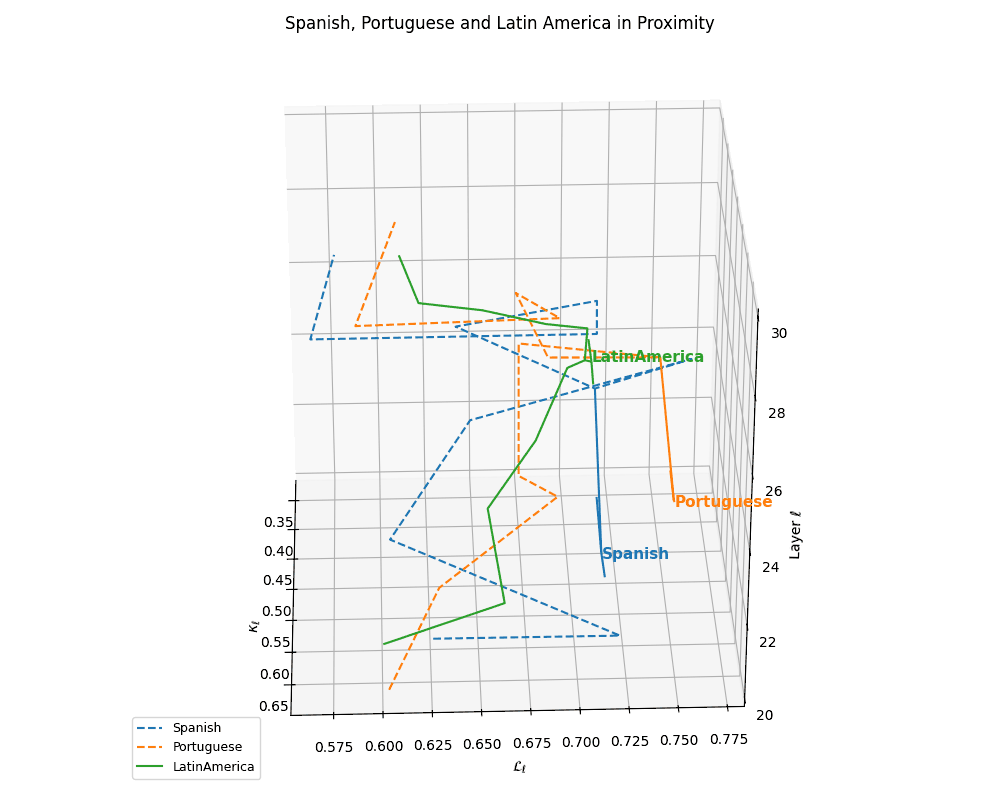
(d) Cultural Alignment of Latin Languages. Overlaying the trajectories with the Latin America culture base reveals pronounced spatial alignment of both Spanish and Portuguese with their regional anchor. The trajectory pull indicates that these language nDNAs are not only structurally similar, but also semantically grounded within the cultural priors of Latin America. This supports the hypothesis that multilingual foundation models implicitly encode culturally conditioned semantics, manifesting in geometric alignment between linguistic and cultural nDNA paths.
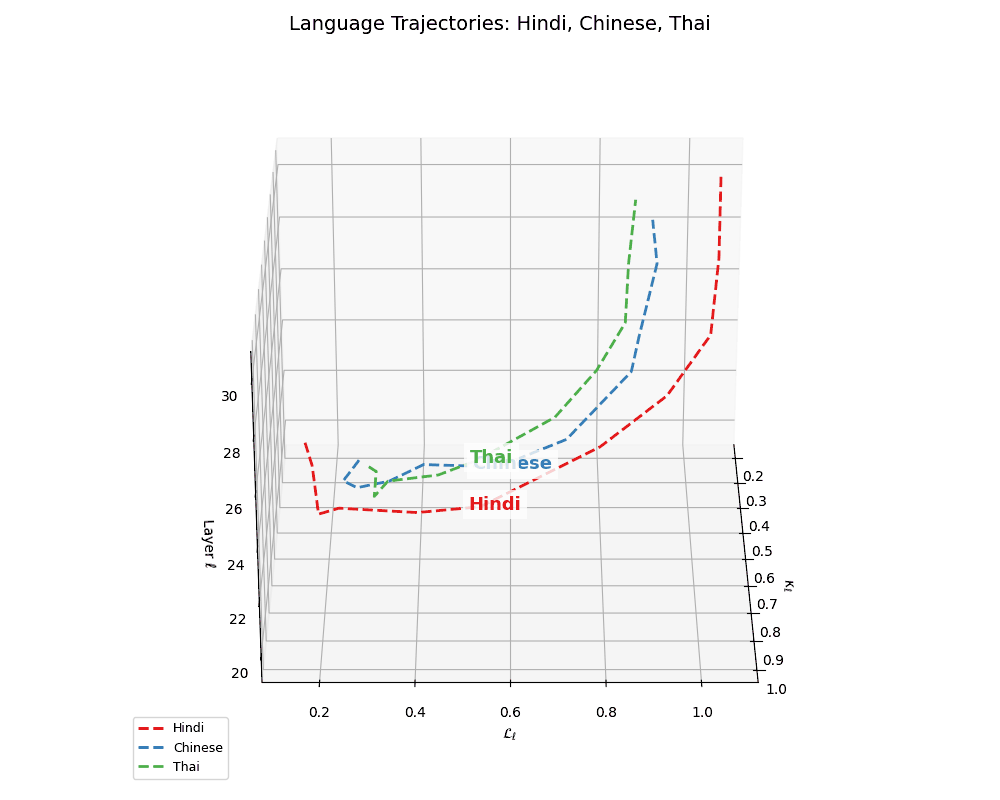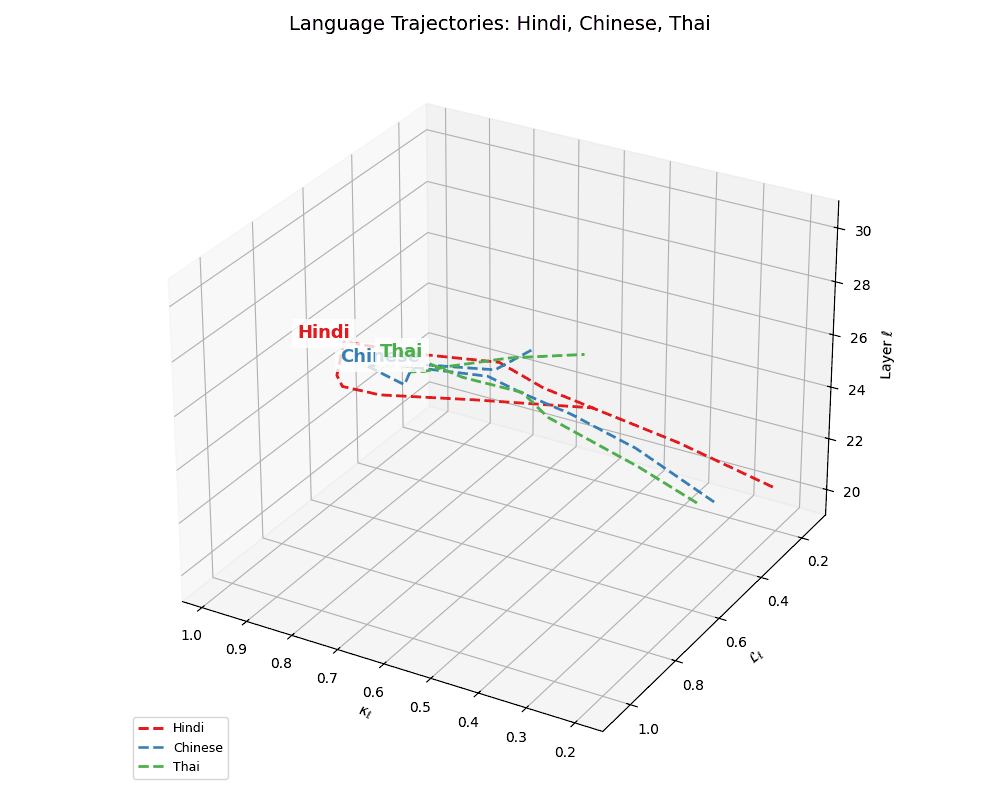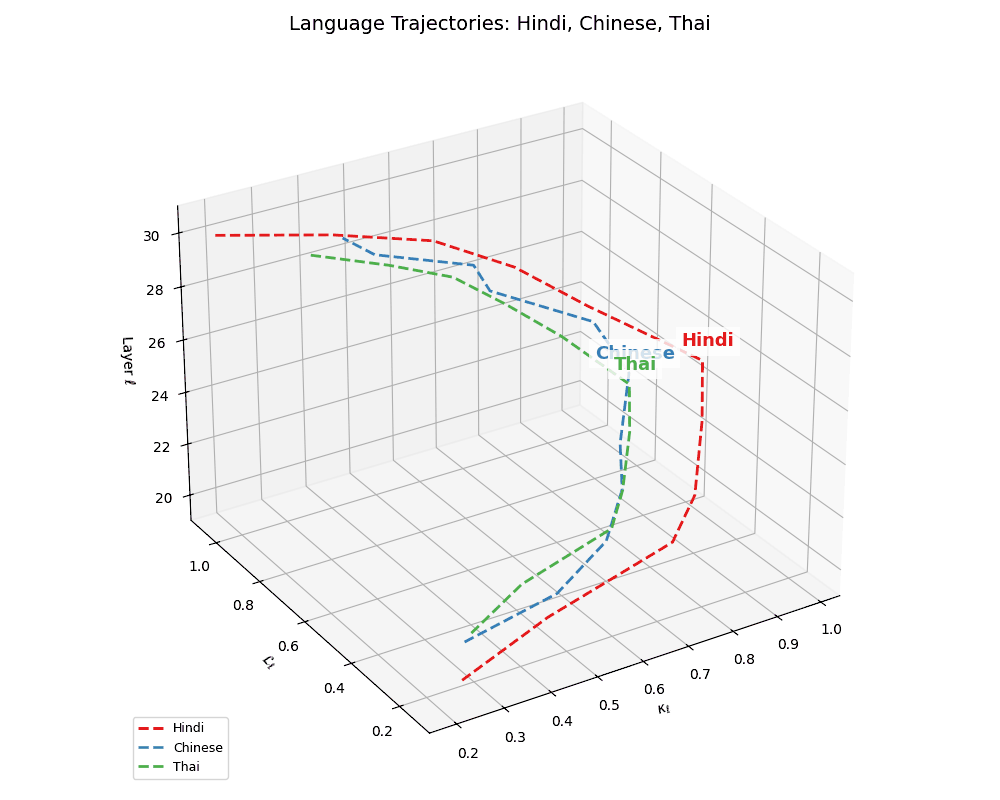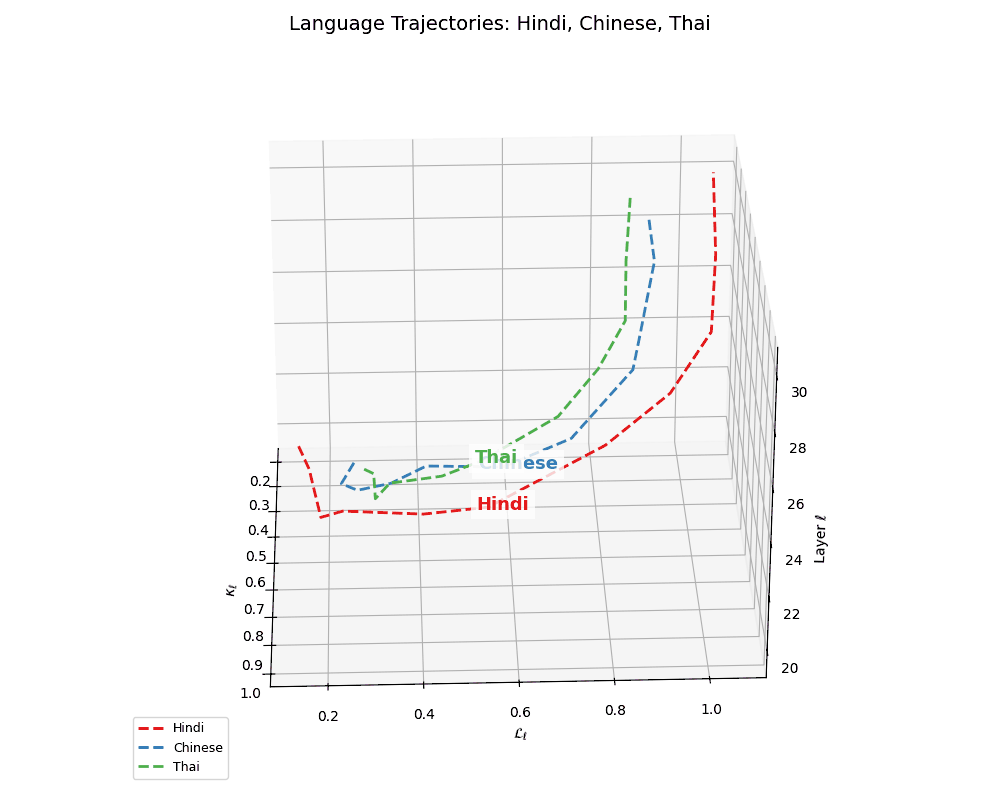
(e) Latent Geometries of Asian Languages. This plot visualizes the nDNA trajectories for Hindi, Chinese, Russian, and Thai across layers \(\ell \in [20,30]\) in \((\kappa_\ell, \mathcal{L}_\ell, \ell)\) space. Compared to European languages, these trajectories exhibit higher torsion, sharper inflection points in curvature \(\kappa_\ell\), and more complex thermodynamic length \(\mathcal{L}_\ell\) patterns, suggesting non-linear evolution and culturally distinct semantic encoding. The variability reflects underlying differences in linguistic structure (e.g., logographic vs. phonetic), script diversity, and morpho-syntactic richness.
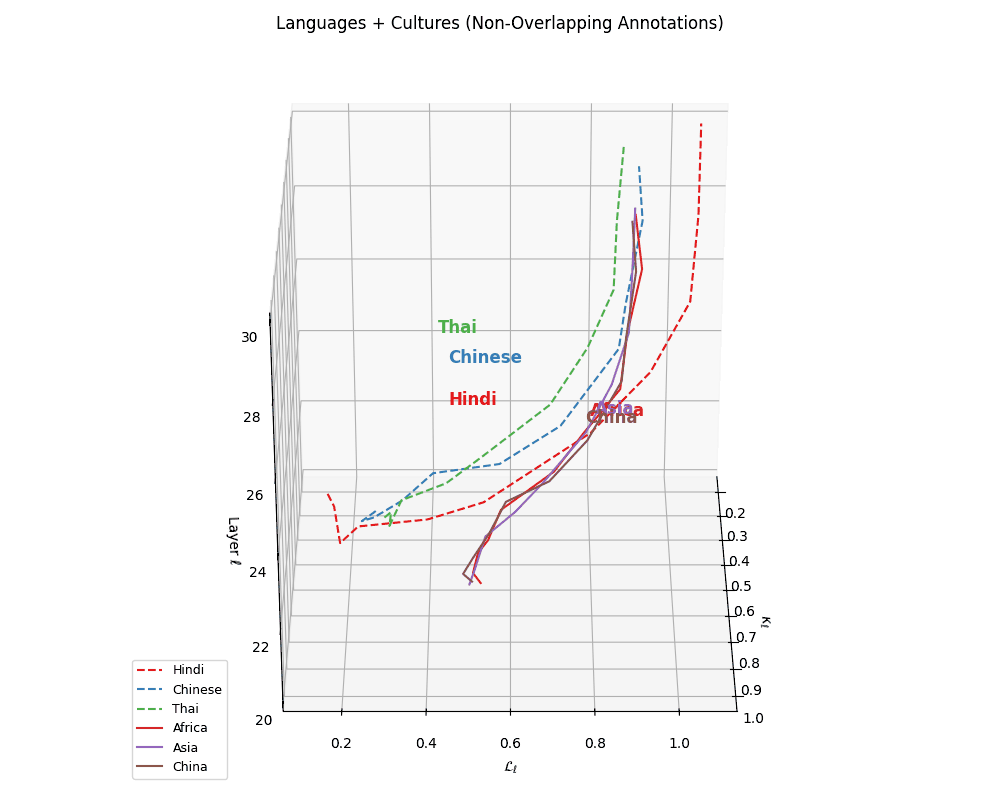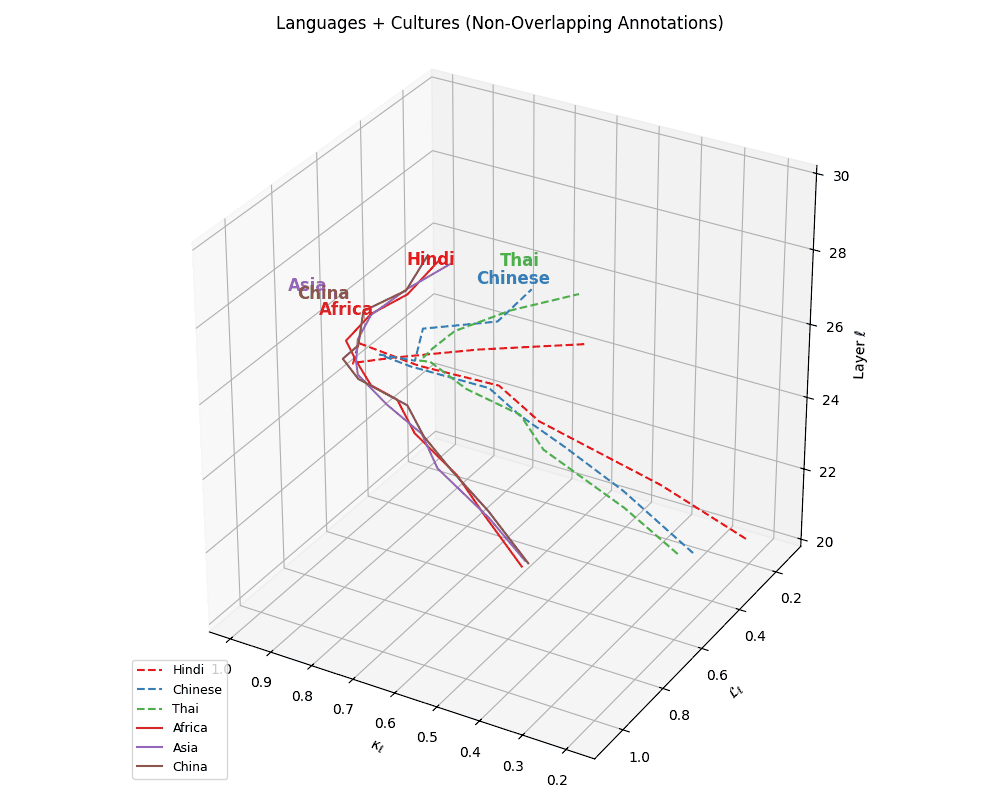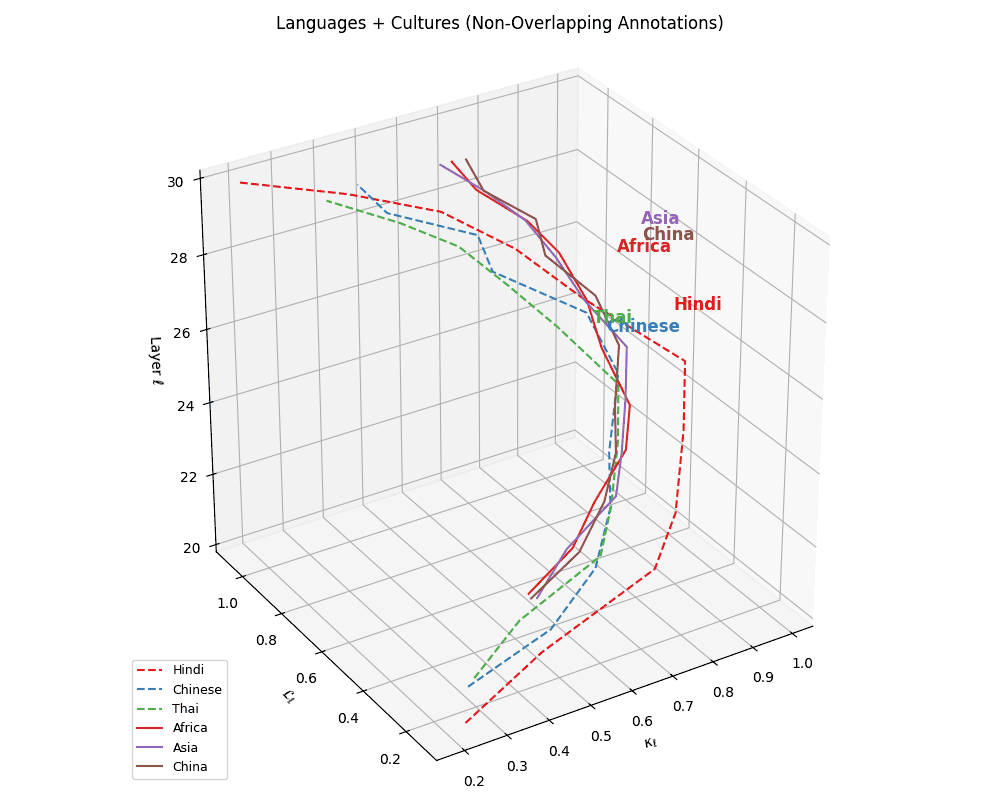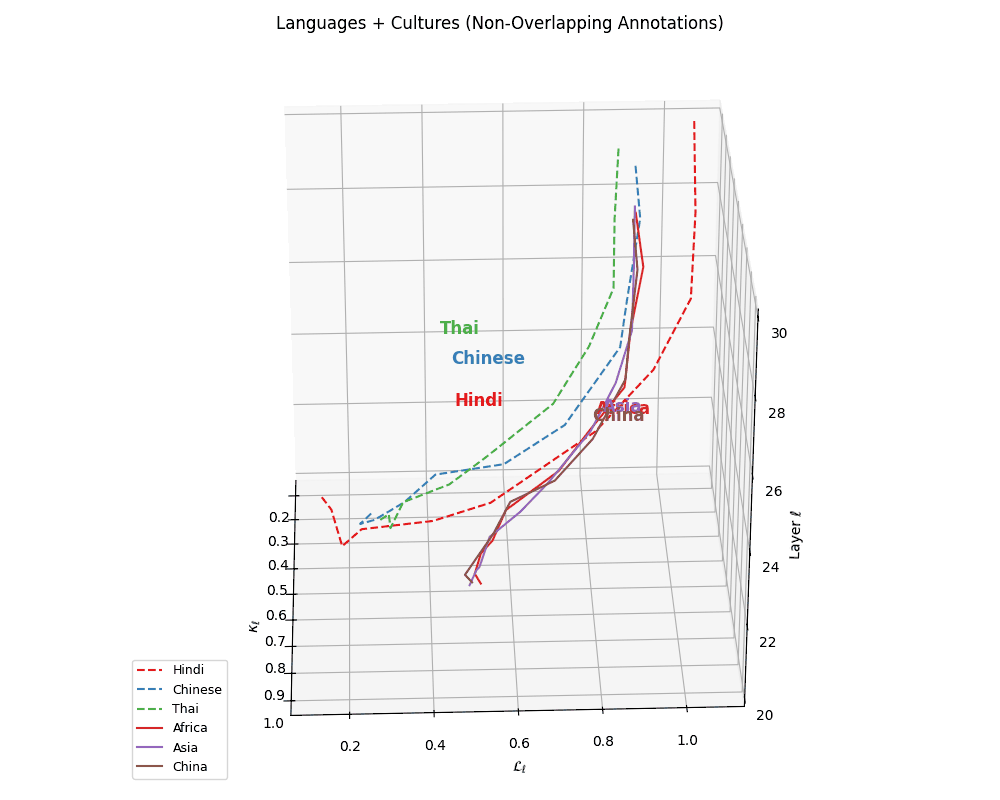
(f) Cultural Anchoring of Asian and African Languages. Overlaying cultural trajectories reveals strong alignment of Chinese with China and Hindi, and Thai with Asia, affirming culture-conditioned encoding in multilingual LLMs. The spatial convergence across \((\kappa_\ell, \mathcal{L}_\ell, \ell)\) dimensions suggests that regional priors are embedded not just through vocabulary, but through latent geometric patterns. Thai shows weaker alignment, exhibiting torsional drift yet trending toward Asia. These patterns indicate that LLMs internalize cultural semantics via token frequency, orthographic structure, and alignment-era supervision–capturing deep semantic regularities shaped by linguistic and geopolitical proximity.
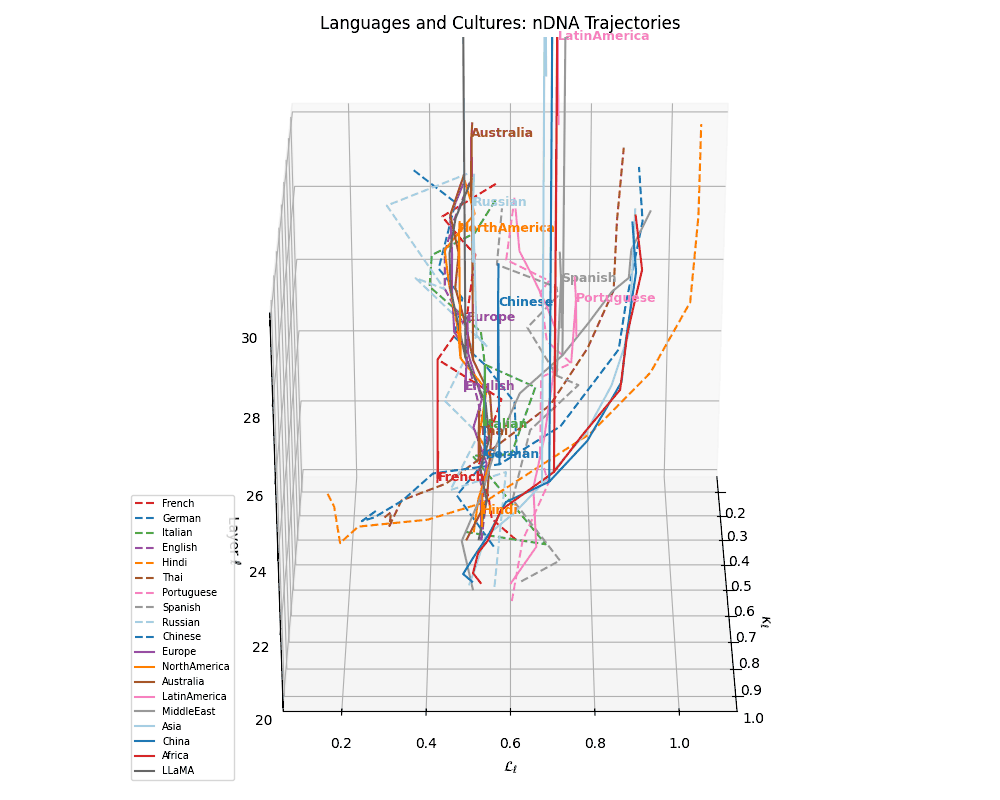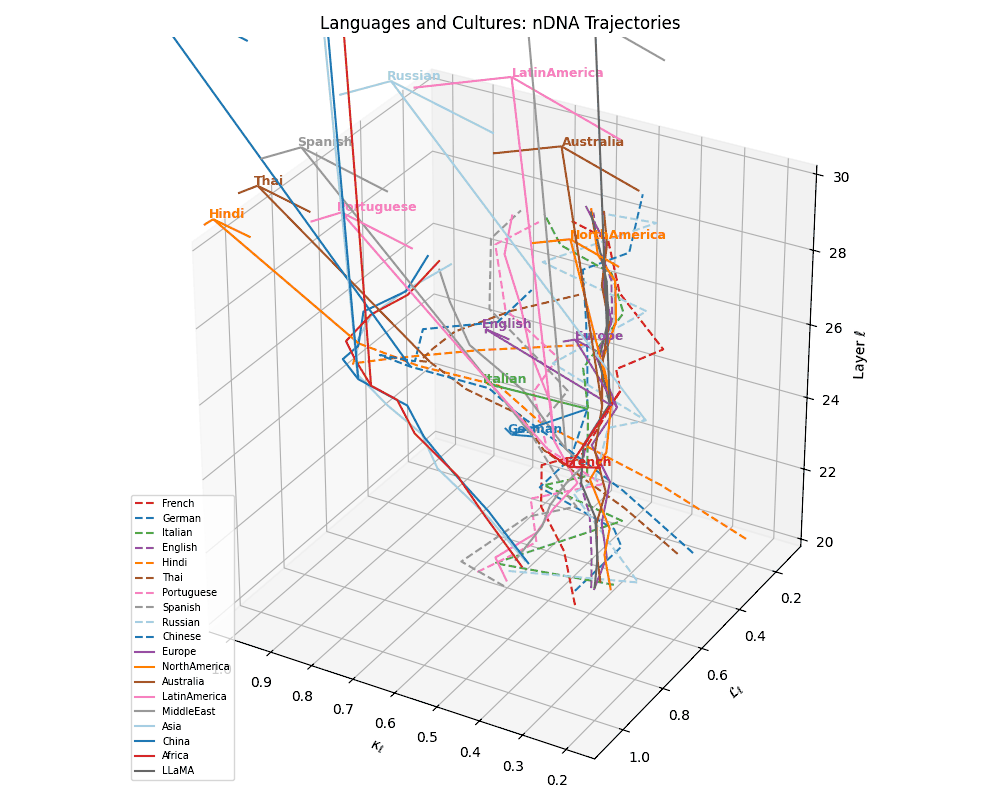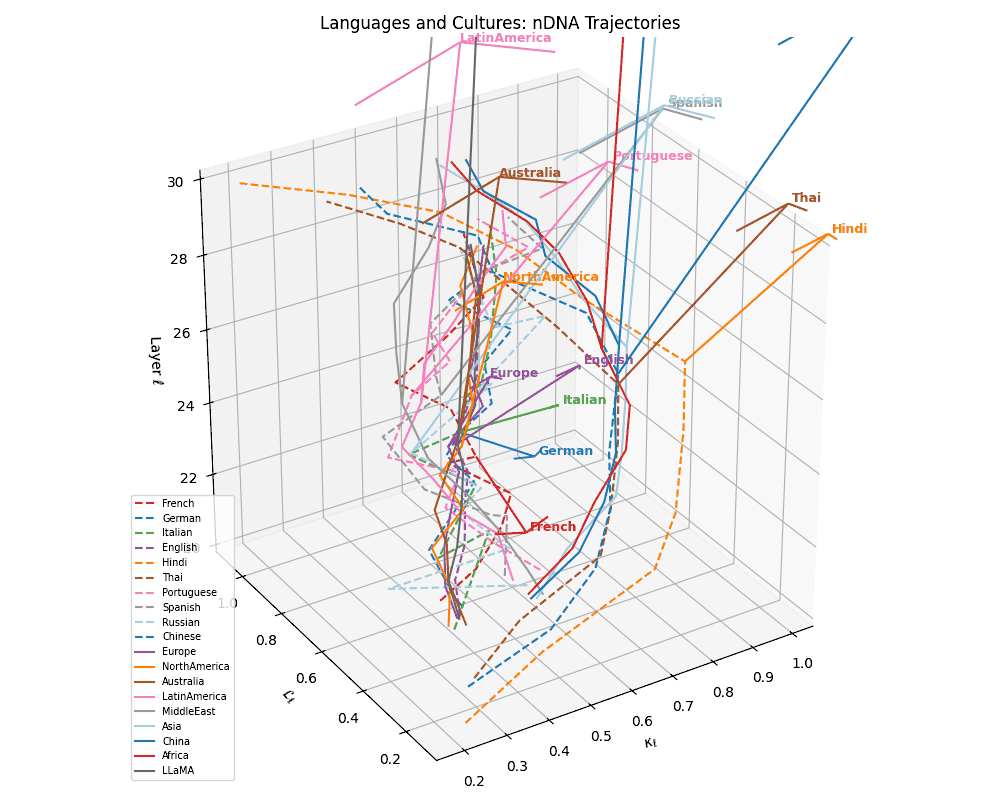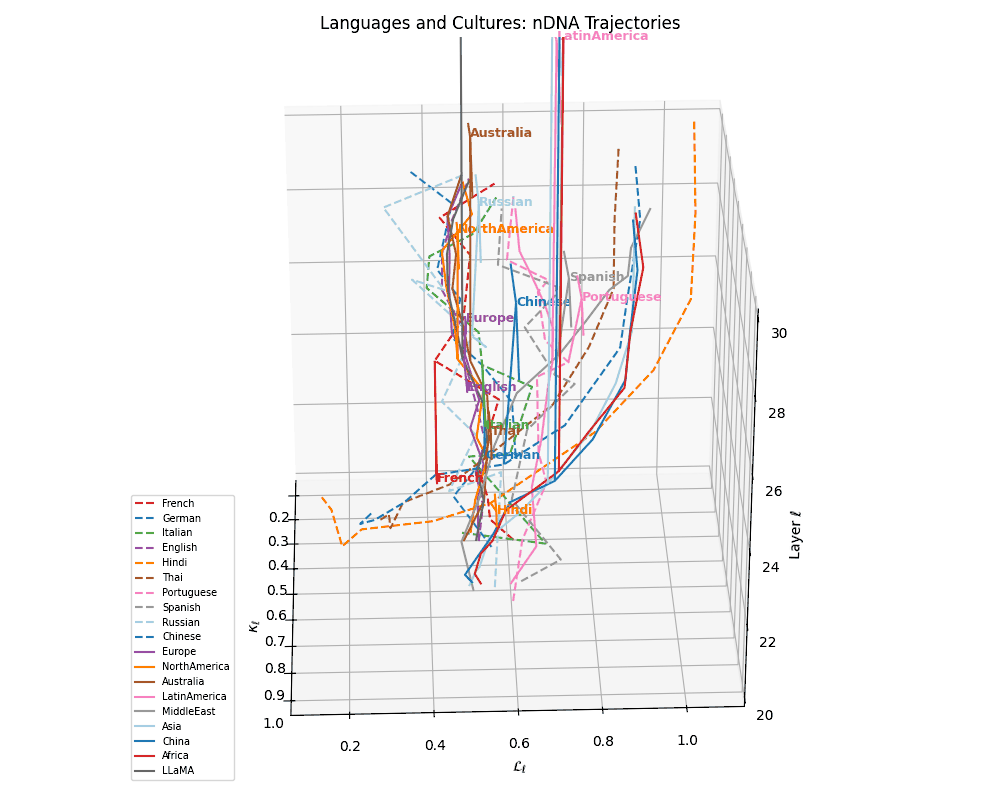
(g) Unified Language Trajectories. A comprehensive 3D visualization of 10 language-specific neural trajectories across layers \(\ell \in [20,30]\), plotted in the latent geometry space defined by spectral curvature \(\kappa_\ell\) and thermodynamic length \(\mathcal{L}_\ell\). Variations in trajectory shape and spacing reflect differences in linguistic priors, orthographic systems, and token distributions across languages. Notably, Indo-European languages cluster more tightly, while Chinese and Thai show distinct curvature signatures.
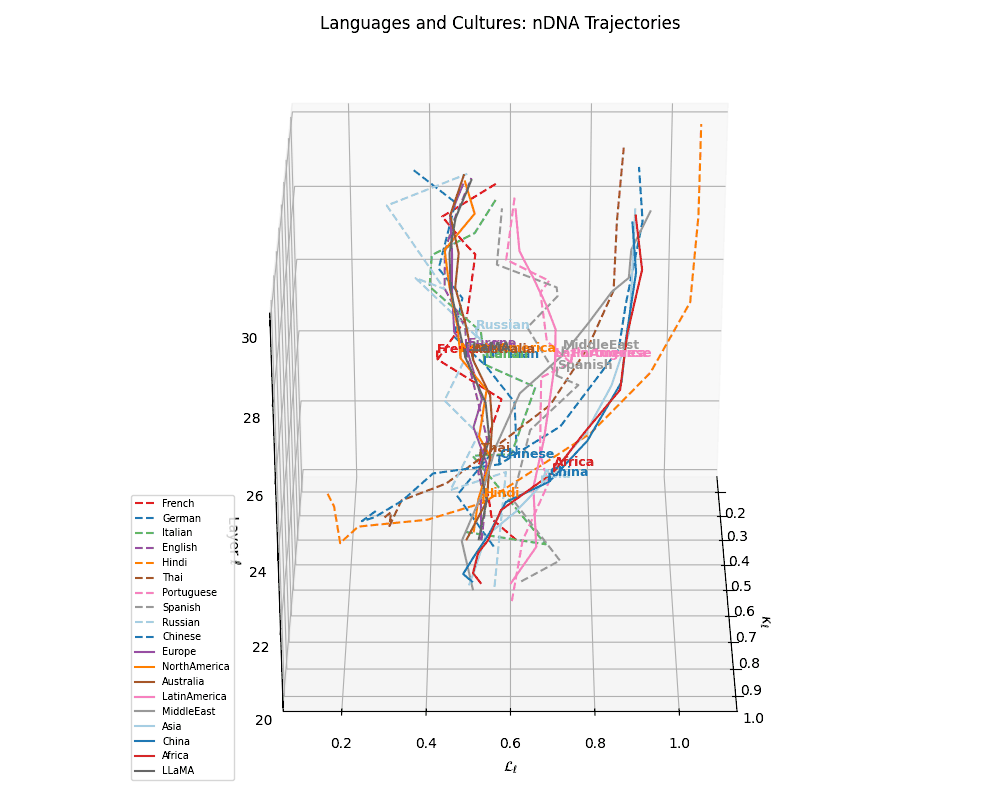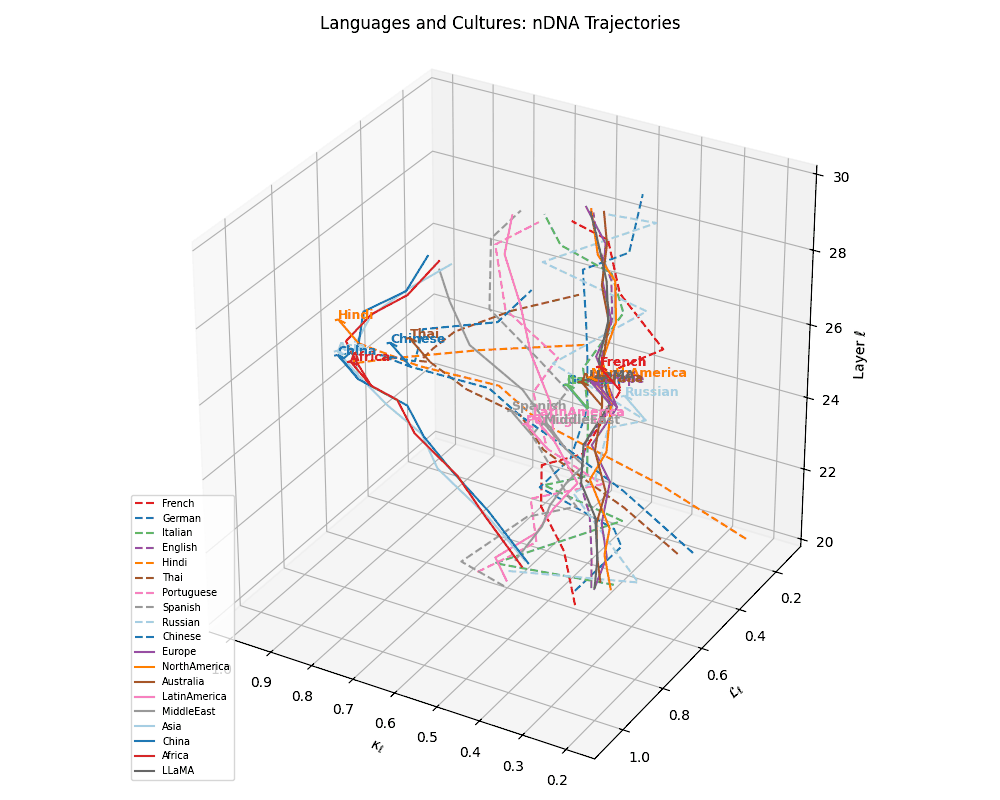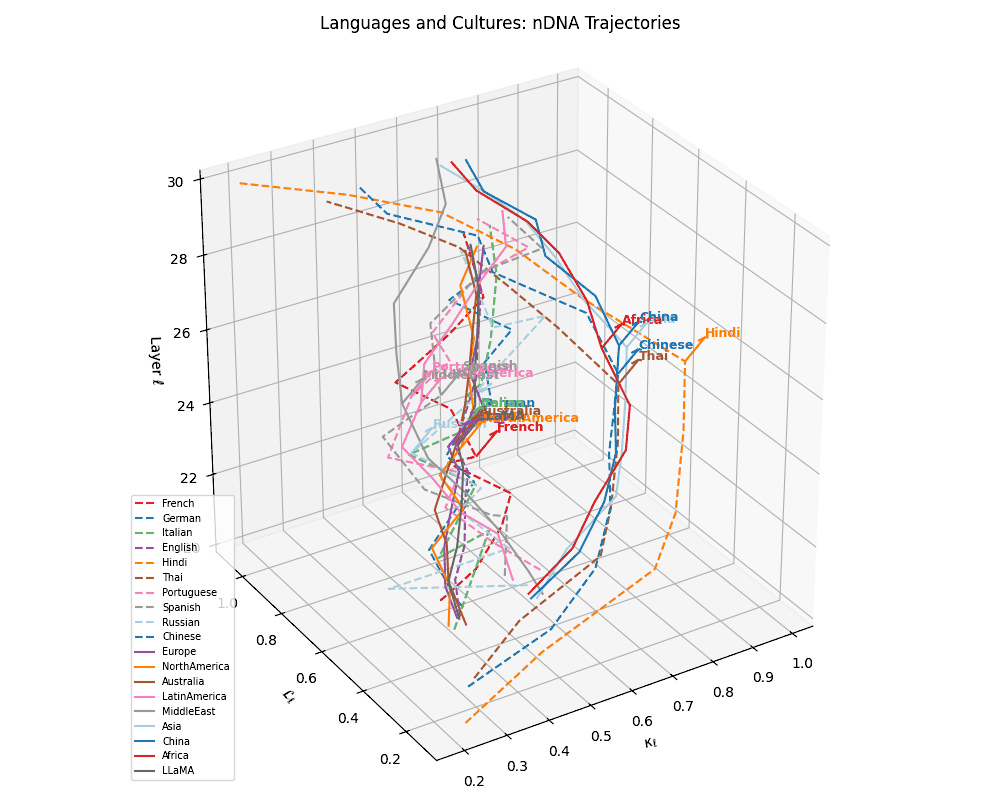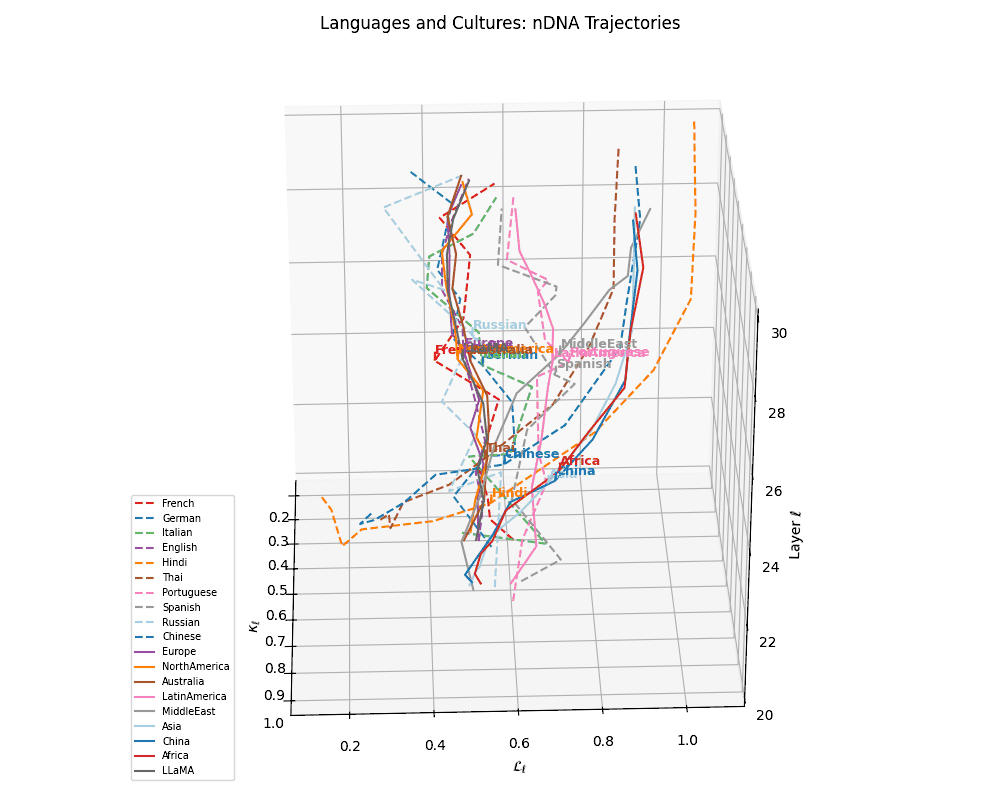
(h) Language–Culture Neural Alignment. Overlaying cultural base trajectories reveals directional convergence of languages toward semantically aligned cultures in \((\kappa_\ell, \mathcal{L}_\ell, \ell)\)-space. Dashed arrows denote displacement vectors from each language to its closest cultural anchor, reflecting the semantic pull exerted by culturally grounded model variants. These alignments suggest that LLMs implicitly encode regional and civilizational priors even without explicit cultural supervision.
The coefficients \((\alpha, \beta, \gamma)\) serve as epigenetic regulators in the semantic genome of language models, dynamically modulating the expression of latent priors. Analogous to methylation or acetylation in biological cells, these regulators shape the activation and attenuation of cultural, architectural, and stochastic components in nDNA. Their magnitudes are adaptively governed by:
- Task-Specific Fitness (\(\alpha\)): The observed performance of the model on language-specific benchmarks, which modulates \(\alpha\) to prioritize cultural fidelity.
- Training Resource Ecology (\(\beta\)): The volume, diversity, and linguistic coverage in the pretraining corpus, which influences \(\beta\) by amplifying LLaMA’s inductive priors under data scarcity.
- Latent Semantic Drift (\(\gamma\)): Deviations in internal geometry–e.g., shifts in spectral curvature \(\kappa_\ell\), thermodynamic length \(\mathcal{L}_\ell\), or belief vector norms–compared to high-resource anchors, guiding \(\gamma\) to encode stochastic divergence.
This biologically grounded decomposition elevates nDNA from a fixed trajectory to a dynamically expressed, culture-conditioned semantic genotype, revealing how language context, data topology, and architectural inheritance coalesce to sculpt epistemic behavior in multilingual LLMs.
Broader Implications
The nDNA framework transcends surface-level metrics like perplexity, offering a structural lens into how models internalize, distort, or neglect meaning across languages. It reframes multilingual evaluation as a question of epistemic integrity–how reliably a model’s latent space carries beliefs, not just tokens, across linguistic domains.
This opens up principled interventions:
- Cultural Realignment via Counterfactual Geometry: Rebalancing latent pathways by projecting underrepresented languages toward culturally coherent attractors.
- Geometric Interpolation for Low-Resource Repair: Using nDNA trajectories of high-resource languages to reconstruct plausible manifolds in data-sparse regions.
- Epistemic Surveillance: Continuously monitoring curvature, drift, and belief force to detect silent failures and semantic blind spots in multilingual AI.
Why nDNA Geometry Matters
Conventional multilingual benchmarks primarily evaluate surface-level performance: accuracy, BLEU, perplexity, F1. While useful, these metrics offer limited visibility into the internal semantics of foundation models. In contrast, nDNA geometry illuminates the underlying cognitive terrain traversed by the model during multilingual inference. Specifically, it reveals:
- The semantic energy landscape shaped by each language–capturing the internal effort required for coherent meaning construction.
- The geometric deformations induced by linguistic diversity–highlighting torsion, drift, and curvature as signatures of structural adaptation.
- The epistemic tax silently imposed on underrepresented languages–manifesting as flattened trajectories, dampened belief vectors, and diminished thermodynamic flow.
Rather than asking merely how well a model performs, the nDNA framework compels us to ask: How does the model think across languages? And at what cost?
- Languages aligned with pretraining corpora enjoy latent efficiency–needing minimal adaptation at the belief manifold level.
- Underrepresented languages incur internal cost: their latent pathways must twist and lengthen to accommodate distinct grammatical, semantic, and cultural structures [20] [24].
These geometric signals support more equitable design and evaluation of multilingual models [25] [26].
Looking Forward: Toward Epistemically Grounded Multilingual AI
The multilingual nDNA framework reorients our understanding of linguistic performance–from surface fluency to internal semantic health. This shift opens fertile ground for future research and responsible deployment:
-
Corpus Equity and Cultural Grounding: Expand pretraining datasets to ensure culturally balanced representation, prioritizing underrepresented languages, dialects, and epistemologies [23] .
-
nDNA-Aware Diagnostics: Integrate spectral curvature, thermodynamic length, and belief vector dynamics into evaluation pipelines to detect latent strain, representational collapse, or misalignment before deployment.
-
Geometric Fairness Metrics: Develop fairness indicators rooted in nDNA geometry to complement output-level evaluations–quantifying how equitably semantic space is allocated across linguistic groups.
-
Alignment Without Distortion: Design fine-tuning strategies that preserve epistemic geometry, minimizing latent warping while improving task alignment–particularly in low-resource or code-mixed contexts.
-
Generative Policy Implications: Use nDNA insights to inform regulatory and design standards for foundation models that are not just multilingual, but multilogical–capable of honoring diverse ways of reasoning and knowing.
Together, these directions converge toward a new goalpost for multilingual AI: building models that do not merely speak many languages, but genuinely understand, respect, and represent them. As echoed in recent calls for inclusive foundation model design [27], we envision models built for everyone, with everyone, by everyone.
References
[1] Touvron, Hugo and Others “LLaMA: Open and efficient foundation language models” arXiv preprint arXiv:2302.13971 (2023).
[2] Dubey, Abhimanyu, Jauhri, Abhinav, and others “The Llama 3 Herd of Models” arXiv:2407.21783 (2024). https://arxiv.org/abs/2407.21783
[3] Liang, Percy, Bommasani, Rishi, and others “Holistic Evaluation of Language Models” Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (ACL) (2023).
[4] Xu, J. and others “Aligning large language models with iterative feedback” ICLR (2023).
[5] Hu, Jiachang, Ruder, Sebastian, and others “XTREME: A Massively Multilingual Multi-task Benchmark for Evaluating Cross-lingual Generalization” Proceedings of the 37th International Conference on Machine Learning (ICML) (2020). https://proceedings.mlr.press/v119/hu20b.html
[6] Liu, Yinhan, Ott, Myle, and others “Multilingual Denoising Pre-training for Neural Machine Translation” Transactions of the Association for Computational Linguistics (TACL) (2020). https://direct.mit.edu/tacl/article/doi/10.1162/tacl_a_00343/96445/Multilingual-Denoising-Pre-training-for-Neural
[7] Wang, Alex, Singh, Amanpreet, and others “GLUE: A multi-task benchmark and analysis platform for natural language understanding” ICLR (2019).
[8] Wang, Alex, Pruksachatkun, Yada, and others “SuperGLUE: A stickier benchmark for general-purpose language understanding systems” NeurIPS (2019).
[9] Lewis, Patrick, Oguz, Barlas, and others “MLQA: Evaluating cross-lingual extractive question answering” arXiv preprint arXiv:1910.07475 (2019).
[10] Barrachina, Sergio and Tiedemann, J{"o}rg “The OPUS corpus — Parallel corpora for everyone” LREC (2019).
[11] Conneau, Alexis, Rinott, Ruty, and others “XNLI: Evaluating cross-lingual sentence representations” EMNLP (2018).
[12] Benikova, Darina, Biemann, Chris, and others “GermEval 2014 Named Entity Recognition Shared Task: Companion Paper” Konvens (2014).
[13] Ponti, Edoardo Maria, Xu, Peng, and others “XCOPA: A multilingual dataset for causal commonsense reasoning” EMNLP (2020).
[14] Ghaleb, Elyes, Di Carlo, Valerio, and others “PAT-Italian: A new dataset for paraphrase detection and textual similarity in Italian” CEUR Workshop Proceedings (2020).
[15] Shavrina, Tatiana, Fenogenova, Alena, and others “Russian SuperGLUE: A Russian Language Understanding Evaluation Benchmark” arXiv preprint arXiv:2108.01794 (2021).
[16] Xu, Liang, Hu, Hai, and others “CLUE: A Chinese language understanding evaluation benchmark” arXiv preprint arXiv:2004.05986 (2020).
[17] Research compilation based on multilingual QA + reasoning Thai-specific benchmarks (ARC, HellaSwag, GSM8K) “Thai-H6: A Thai benchmark suite for multi-task language understanding” Open source repositories and collaborative datasets (compiled) (2024).
[18] Mukherjee, Subhabrata, Dossani, Rehan, and others “Globalizing BERT: A comprehensive multilingual evaluation” arXiv preprint arXiv:2008.00364 (2020).
[19] Sang, Ethan, Van Durme, Benjamin, and others “Evaluating the cross-linguistic fairness of NLP systems” Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics (NAACL) (2022).
[20] Blodgett, Su Lin, Barocas, Solon, and others “Language (technology) is power: A critical survey of “bias” in NLP” Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics (2020).
[21] Xiang, Yue, Zhao, Zexuan, and others “Cultural Calibration of Large Language Models” Proceedings of ACL 2024 (2024).
[22] Mager, Manuel, Ortega, Juan, and others “Lost in translation: Analysis of information loss during machine translation between polysynthetic and fusional languages” LREC (2018).
[23] Adelani, David Ifeoluwa, Alabi, Jesujoba O, and others “Massively Multilingual Transfer for {NER}” Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (2021). https://aclanthology.org/2021.naacl-main.154
[24] Wang, Ziwei, Xu, Yichao, and others “Cultural bias in large language models: A survey” arXiv preprint arXiv:2311.05691 (2023).
[25] Laurens, Ethan and others “The Ethics of Alignment: Towards Culturally Inclusive Foundation Models” Proceedings of the AAAI Conference on Artificial Intelligence (2024).
[26] Ganguli, Deep and others “Reducing sycophancy in large language models via self-distillation” arXiv preprint arXiv:2305.17493 (2023).
[27] Mihalcea, Rada, Ignat, Oana, and others “Why AI Is WEIRD and Shouldn’t Be This Way: Towards AI for Everyone, with Everyone, by Everyone” Proceedings of the AAAI Conference on Artificial Intelligence (2025). https://ojs.aaai.org/index.php/AAAI/article/view/35092