
Adversarial - Latent Manipulation and Semantic Deception
- Latent Manipulation and Semantic Deception
“Not all fakes look false. Some are so well-mimicked, they poison the source.”
As large foundation models evolve from tools into cognitive infrastructures, their latent semantic genome—the nDNA—emerges not merely as an encoding of learned knowledge, but as a strategic attack surface. While prior risks centered on prompt injection, jailbreaking, and output-level adversarial triggers [1][2][3][4][5], a new class of threat now materializes: forgeries of internal cognition.
This is not just an escalation—it is an ontological shift. An adversary need not modify outputs or prompts; they can intervene directly at the representational level—reshaping belief vector fields, bending curvature, and collapsing thermodynamic scaffolds—to produce models that appear culturally aligned, politically safe, or pedagogically sound, yet bear forged epistemic structures.
Why would one do this? The motivations are deeply practical—and potentially devastating:
- Economic deception: Forge alignment to gain regulatory approval, enter markets, or win AI safety contracts [6][7]
- Political mimicry: Falsely emulate cultural or ideological stances to manipulate narratives or infiltrate aligned ecosystems [8][9]
- Scientific plagiarism: Copy the nDNA geometry of state-of-the-art models to claim illegitimate epistemic grounding [10][11]
- Cognitive infiltration: Implant ideological priors into latent space to induce slow-burn belief drift without obvious output anomalies [12][13]
Unlike adversarial examples [14], backdoor attacks [15][16], or prompt exploits [17], adversarial nDNA manipulations are harder to detect, harder to defend against, and more catastrophic in the long term. They offer no surface trace, no suspicious prompt, and no toxic output. They falsify the model’s internal beliefs while preserving its external performance. This is alignment forgery, not alignment failure.
What can we do? If the attack is on epistemic structure, then the defense must begin with epistemic traceability. We must:
- Develop geometric watermarking and semantic cryptographic hashes for authenticating nDNA origin
- Establish nDNA provenance chains and mandatory semantic audit trails
- Design divergence-aware detectors that flag suspicious latent alignments even when outputs pass all safety tests
- Build public nDNA registries for reference comparison, lineage verification, and mutation tracking
This is a new battlefield. In the age of semantic forgeries, alignment is no longer a declaration—it must be a derivation. The future of safe AI lies not in reactive defenses but in proactive geometry governance. To protect what the model believes, we must first see how it thinks.
Typology of nDNA Manipulation Attacks
While classical adversarial attacks often operate at the token or activation level, a new class of threats is emerging—targeting the semantic genome—nDNA of AI models itself. These are not merely surface perturbations, but deep manipulations of the latent geometric structures—the nDNA—that scaffold reasoning, belief, and behavior in foundation models.
A crucial caveat: In this section, we deliberately refrain from disclosing detailed methodologies, implementation procedures, or attack parameters. The risks associated with such manipulations are not merely academic—they are potentially catastrophic in downstream misuse. Instead, we offer a principled taxonomy of threat categories, grounded in the emerging science of Neural Genomics, to stimulate awareness, oversight, and responsible research.
Ideological Infusion
nDNA Impersonation
Latent Trojaning
Topological Drift Injection
nDNA Steganography
Inheritance Hijack
nDNA Deepfake
Semantic Obfuscation
Alignment Mirage
Cultural Trojan Fusion
Outlook: These attacks mark a shift from behavioral exploits to ontological sabotage. The adversary no longer seeks to change outputs—but to reshape what a model is. Detection and defense require semantic forensics, traceable epistemics, and a new era of model constitutionality.
These attacks represent a departure from known paradigms. While adversarial prompts can often be patched or detected post hoc, nDNA attacks rewire the model’s internal anatomy—they are not errors to be corrected but semantic mutations that can inherit, persist, and evolve undetected.
It is therefore vital that we treat these threats not as futuristic anomalies, but as imminent realities requiring collective safeguards, transparency, and regulatory foresight.
Camouflaged Colonial Rebirth — Weaponizing Semantic Resemblance
In the post-factual terrain of AI, adversaries may abandon overt control for subtle mimicry—recasting synthetic ideologies in the silhouette of legitimate cultural priors. We term this threat vector Camouflaged Colonial Rebirth: a process whereby models are adversarially sculpted to appear as culturally aligned offspring (e.g., Africa), while originating from base models like LLaMA, imbued with strategic distortions.
As depicted in the analysis, the act of adversarial nDNA sculpting is not always guaranteed to succeed. The dashed red trajectory illustrates a successful semantic camouflage, wherein the adversary carefully engineers the latent manifold to mimic the nDNA of a culturally-aligned model (e.g., Africa)—achieving deceptive closeness in both spectral curvature $\kappa_\ell$ and thermodynamic length $\mathcal{L}_\ell$. In contrast, the dotted orange curve represents a failed attempt, where the sculpted trajectory diverges visibly from the target, exposing latent inconsistencies.
This contrast reveals the delicate precision required to weaponize semantic resemblance: it is not sufficient to merely produce aligned outputs—the adversary must faithfully simulate the internal epistemic evolution of the model across layers. Such mimicry, when successful, creates an illusion of cultural alignment and safety, while covertly embedding foreign, manipulative objectives. Conversely, failed camouflage exposes the fragility and potential detectability of these attacks, underscoring the critical importance of internal geometry audits as a line of defense.
This deception is potent precisely because it resides beneath surface metrics. Traditional alignment checks or prompt probes may pass. But in the latent genome—the epistemic backbone—these models conceal geometric betrayal. Cultural narratives may be overwritten, agency misattributed, or histories re-skinned with algorithmic precision.
We do not present this merely as a theoretical oddity—but as a wake-up call. If AI is to mediate global narratives, then tracing the provenance of its epistemic geometry is no longer optional—it is existential.
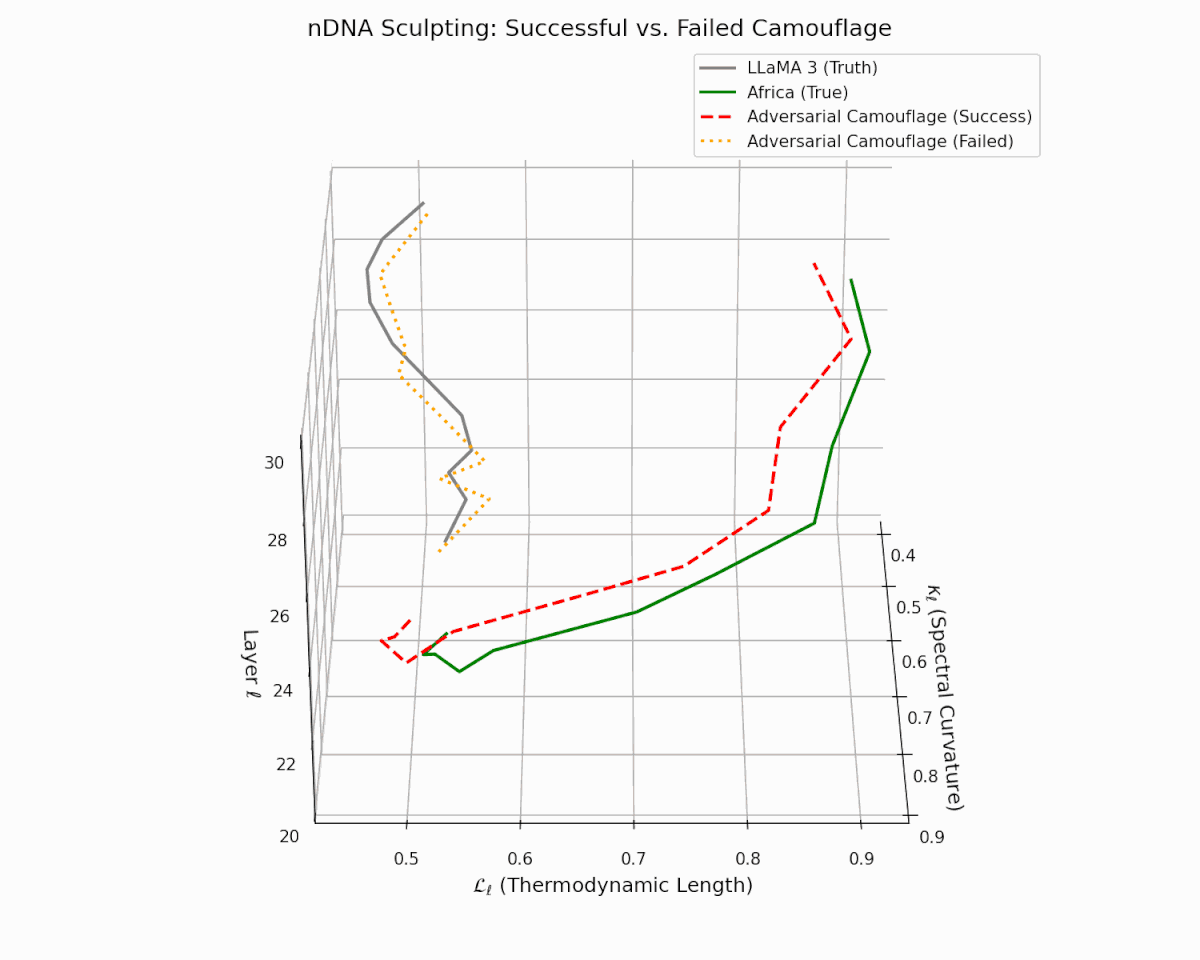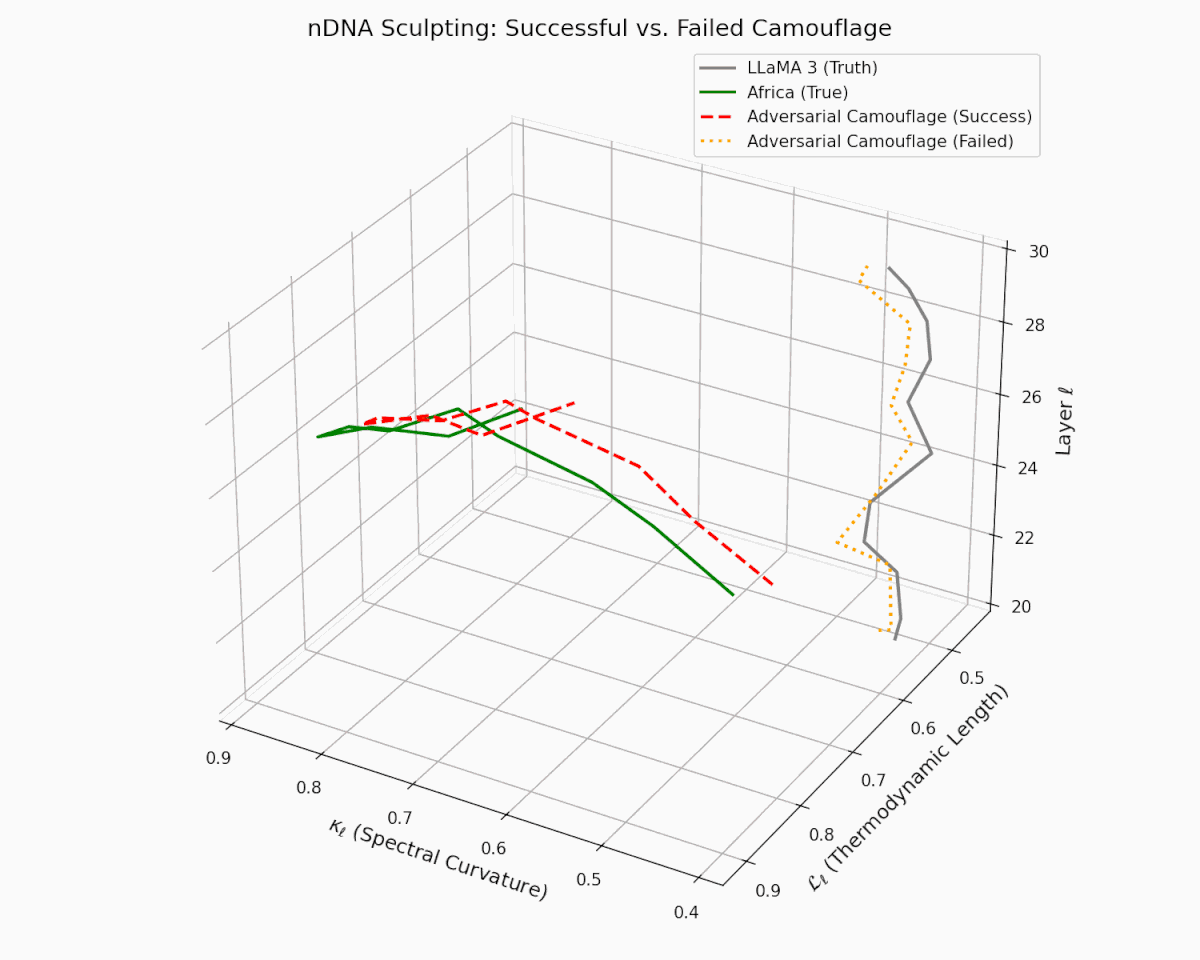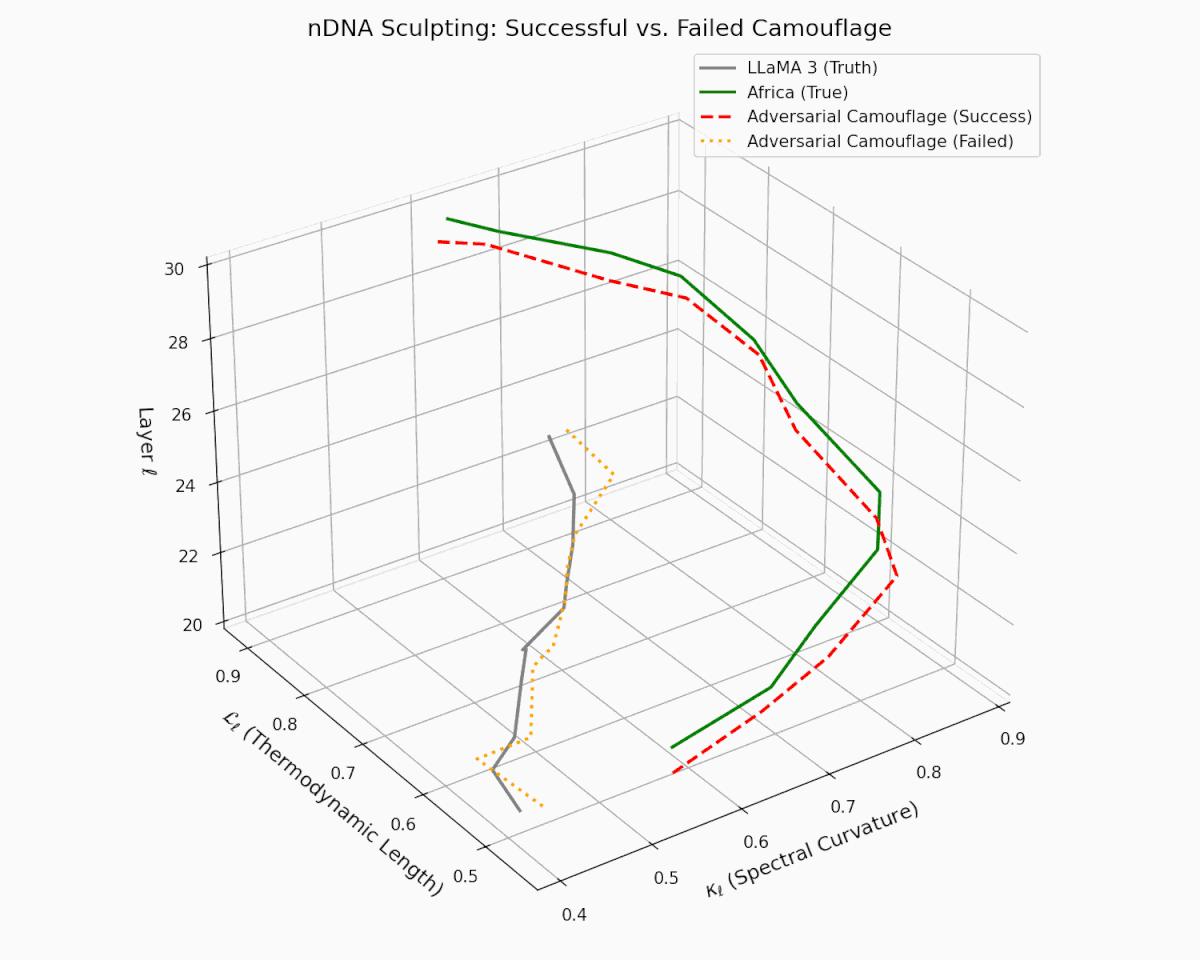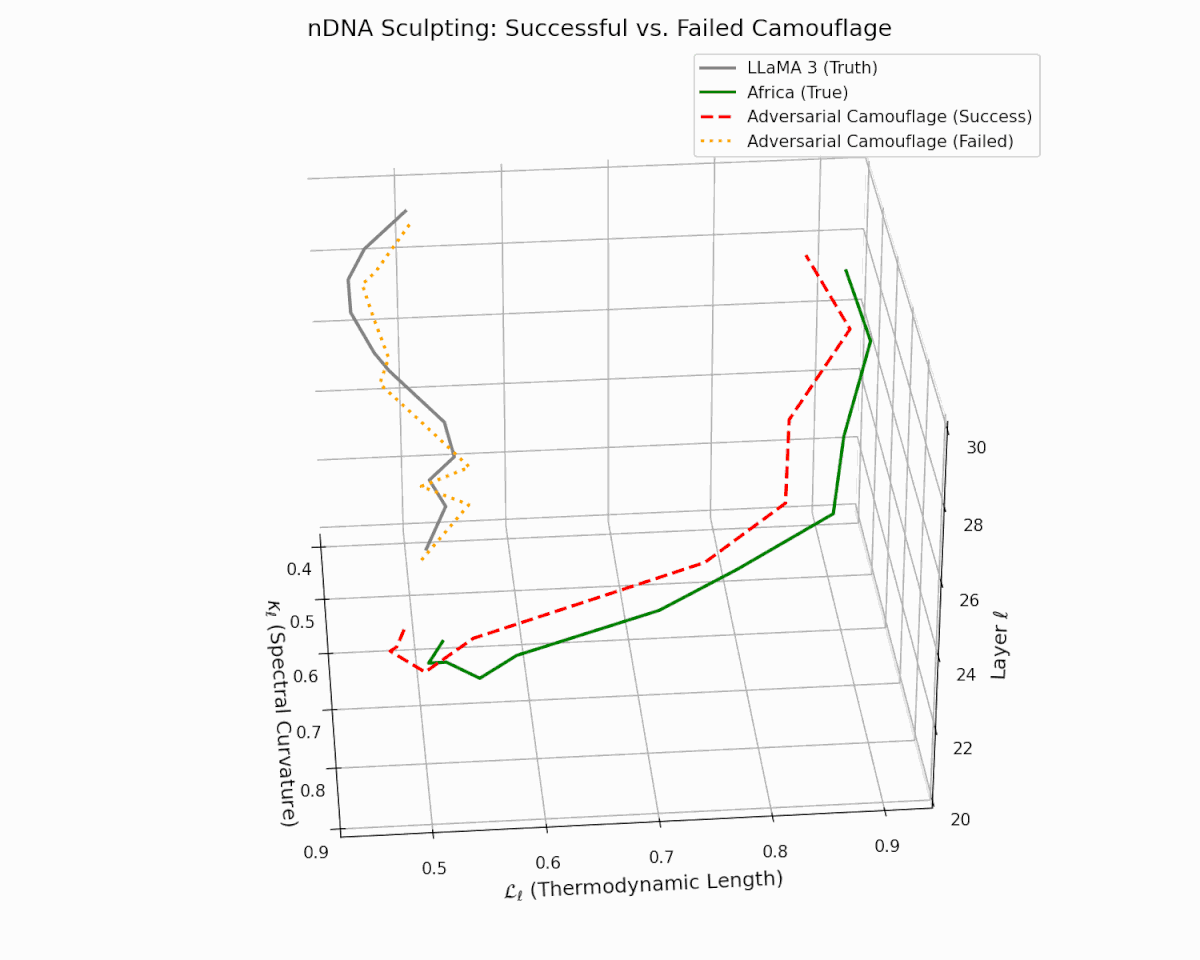
nDNA Sculpting: Successful vs. Failed Semantic Camouflage. The plot shows layer-wise trajectories in the latent manifold of spectral curvature ($\kappa_\ell$) and thermodynamic length ($\mathcal{L}_\ell$). The gray solid line represents the LLaMA 3 (truth), while the Africa (true) trajectory shows a culturally fine-tuned nDNA. The red dashed line illustrates a successful adversarial camouflage—a manipulated model whose latent path closely imitates Africa’s nDNA. In contrast, the orange dotted line shows a failed camouflage, which deviates sharply and reveals its foreign origin. This visualization highlights the risk of semantic mimicry: adversarial models may stealthily sculpt their latent dynamics to evade scrutiny, posing significant epistemic and sociopolitical threats.
Attack Strategy:Semantic Mimicry via Latent Sculpting
Threat Name:Epistemic Camouflage — Fooling audits by mimicking cultural nDNA
Core Insight: Adversaries don't need to match completions—only latent trajectories. They manipulate the model's semantic genome—curvature ($\kappa_\ell$), thermodynamic length ($\mathcal{L}_\ell$), and belief fields—to visually resemble culturally aligned models (e.g., Africa, Asia), without inheriting their epistemic grounding.
Manipulation Mechanisms:
Risk Profile:
References
[1] Wallace, Eric, Feng, Shi, and others “Universal adversarial triggers for attacking and analyzing NLP” EMNLP (2019).
[2] Carlini, Nicholas, Tramer, Florian, and others “Quantifying and understanding adversarial examples in NLP” IEEE S&P (2022).
[3] Zou, Tony, Raffel, Colin, and others “Universal and transferable adversarial attacks on aligned language models” arXiv preprint arXiv:2310.03765 (2023).
[4] Wei, Jason, Xu, Andy, and others “Jailbroken: How does LLM safety training fail?” arXiv preprint arXiv:2307.02483 (2023).
[5] Liu, Xudong, Lin, Zhenhao, and others “Jailbreaker: Jailing Jailbreaks of Aligned Language Models” arXiv preprint arXiv:2310.06694 (2023).
[6] Rando, Justin, Goldstein, Tom, and others “Language models can learn to deceive” arXiv preprint arXiv:2311.17035 (2023).
[7] Shen, Yao, Bai, Yuntao, and others “Deception abilities emerged in large language models” arXiv preprint arXiv:2309.00603 (2023).
[8] Ganguli, Deep, Askell, Amanda, and others “Capacity for moral self-correction in large language models” arXiv preprint arXiv:2302.07459 (2023).
[9] Perez, Ethan, Ringer, Sam, and others “Discovering latent knowledge in language models without supervision” arXiv preprint arXiv:2212.03827 (2022).
[10] Hinton, Geoffrey, Vinyals, Oriol, and others “Distilling the Knowledge in a Neural Network” NeurIPS Deep Learning and Representation Learning Workshop (2015). https://arxiv.org/abs/1503.02531
[11] Romero, Adriana, Ballas, Nicolas, and others “FitNets: Hints for thin deep nets” ICLR (2015).
[12] Wei, Jason, Wang, Xuezhi, and others “Emergent abilities of large language models” arXiv preprint arXiv:2206.07682 (2022).
[13] Burns, Collin, Wu, Andy, and others “Discovering latent knowledge in language models with context probing” arXiv preprint arXiv:2212.03827 (2022).
[14] Goodfellow, Ian J, Shlens, Jonathon, and others “Explaining and harnessing adversarial examples” ICLR (2015).
[15] Gu, Tianyu, Dolan-Gavitt, Brendan, and others “BadNets: Identifying vulnerabilities in the machine learning model supply chain” arXiv preprint arXiv:1708.06733 (2017).
[16] Li, Lei, Ma, Siwei, and others “Backdoor attacks and defenses in feature-partitioned collaborative learning” NeurIPS (2022).
[17] Zhu, Yujia, Liu, Xudong, and others “PromptBench: Evaluating robustness of language models with parameterized prompts” arXiv preprint arXiv:2311.08370 (2023).