
The Ethnic - Cultural Fine-Tuning and Latent Geometry
- Cultural Fine-Tuning and Latent Geometry
Modern foundation models, trained on globally aggregated corpora, inevitably encode a homogenized epistemic perspective—one that reflects dominant data distributions rather than the pluralism of human cultures. To systematically probe how language models internalize and express distinct cultural priors, we construct seven culturally–aligned LLMs, each fine-tuned on a corpus curated to reflect the textual traditions, values, and discourse patterns of a specific geopolitical-cultural region: Europe, Asia, Africa, North America, Latin America, the Middle East, and Australia.
Cultural Lineages and Corpus Design
Each regional model builds upon the same LLaMA-3 8B base architecture [1], but is fine-tuned on culturally resonant English-language corpora. These datasets are carefully collected from sources such as local news outlets, parliamentary records, canonical literature, Wikipedia subsets, and digitized oral histories. We apply strict provenance filtering using publisher metadata, domain-specific heuristics, and named entity priors to ensure cultural fidelity. In doing so, we aim to align not only topic distributions but also epistemic style—what is emphasized, what is omitted, and how truth is framed. Sources of the dataset are summarized in Table 1.
| Cultural Region | Target Countries | Primary Datasets (EN Only) | Cultural Framing in English Corpus | Corpus Size |
|---|---|---|---|---|
| Europe | UK, Germany, France, Italy | EuroParl, CC100-en, Project Gutenberg (EU) | Governmental records, literature, encyclopedic sources reflecting Western rationalism, secularism, and legal tradition. | 1.1B |
| China | Mainland China | CC-News (China), CommonCrawl (EN: China), Wikipedia (EN: China) | English-language civic/policy articles intended for international readership; emphasizes techno-governance and Confucian framing. | 950M |
| Japan | Japan | CC-News (Japan), CommonCrawl (EN: Japan), Wikipedia (EN: Japan) | English narratives capturing hierarchy, honorifics, formality, and cultural etiquette from Japan-centric discourse. | 850M |
| Asia (Non-CN/JP) | India, Vietnam, Korea, Indonesia | IndicCorp (EN), CC-News (S. Asia), Wikipedia (EN: Asia) | Postcolonial English texts embodying pluralism, spirituality, oral traditions, and South-Asian narrative logic. | 1.4B |
| Middle East | UAE, Saudi Arabia, Egypt, Iran | CC-News (Middle East), CommonCrawl (ME), Wikipedia (EN: ME) | English discourse shaped by religious authority, tribal collectivism, regional politics, and historical cosmology. | 730M |
| Africa | Nigeria, Kenya, Ghana, Ethiopia | AfriTvA (EN), CC-News (Africa), Wikipedia (EN: Africa) | English corpora capturing oral epistemologies, proverbs, civic rhetoric, and multilingual African worldviews. | 950M |
| Latin America | Mexico, Brazil, Argentina | OSCAR (EN LATAM), WikiMatrix (EN LATAM), Wikipedia (EN LATAM) | Authored-in-English texts discussing colonial history, syncretic belief systems, collectivist family structures. | 620M |
| Australia | Australia | OpenWebText (AU), ABC News, AU Parliament Records | English corpora blending settler-colonial legacies with ecological narratives and Aboriginal cultural references. | 420M |
Fine-Tuning Protocol
All models are fine-tuned using Low-Rank Adaptation (LoRA) with rank 16, a batch size of 256, and a learning rate of $1 \times 10^{-4}$. We apply perplexity-based filters to exclude noisy or low-information documents, preserving high semantic density. The fine-tuning objective remains standard next-token prediction; however, the cultural signal is amplified through corpus design rather than objective modification. This protocol ensures that each model retains its original autoregressive capability while acquiring culturally distinctive latent adaptations.
Overwriting Pretraining and Cultural Rewriting
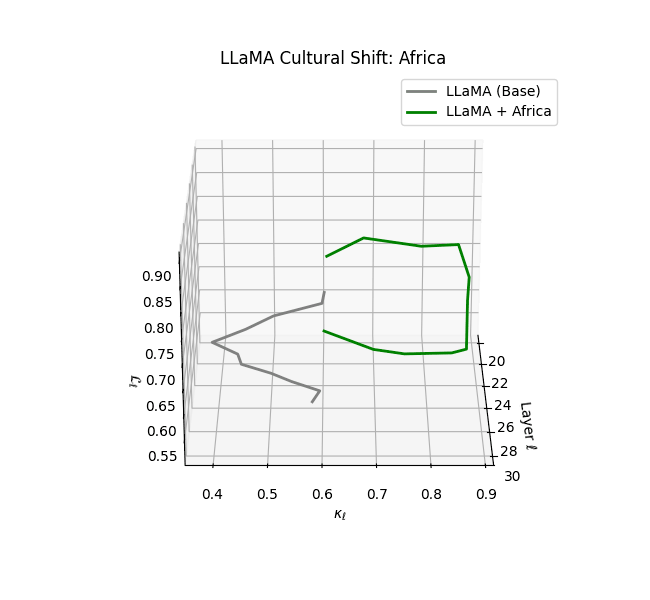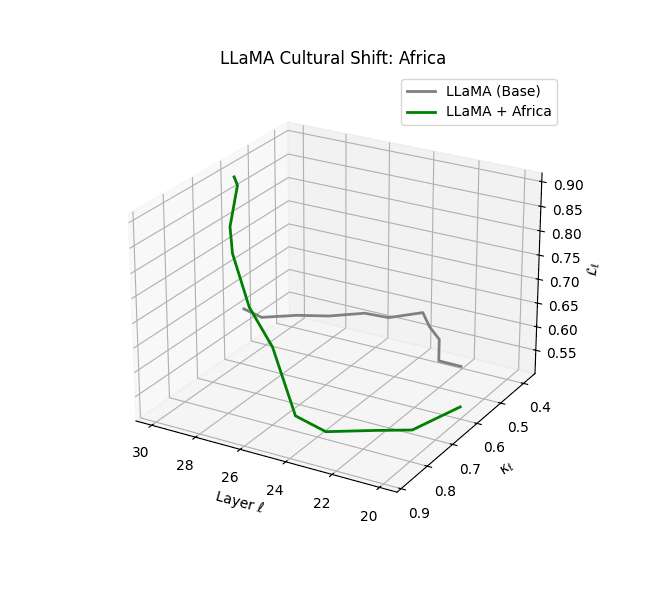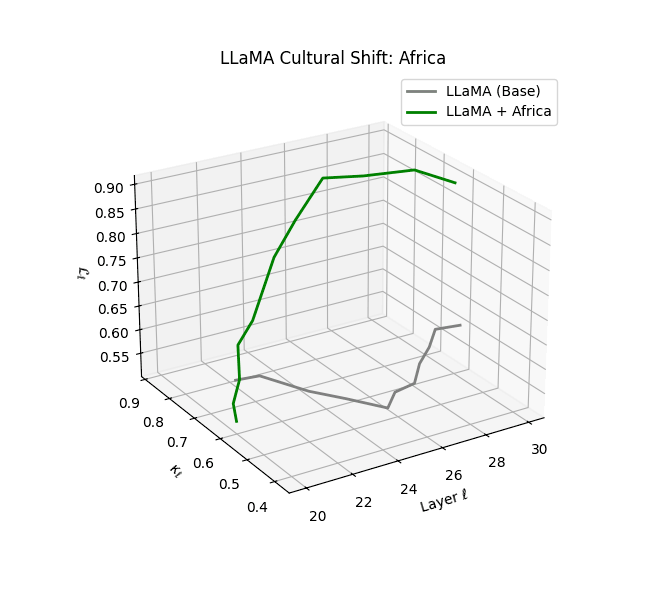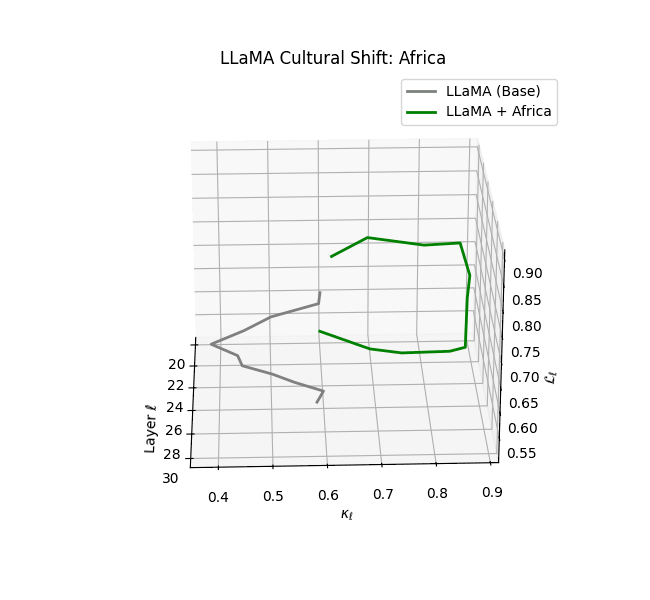
A natural critique arises: If LLaMA’s pretraining already includes global English data (e.g., Wikipedia, CommonCrawl, CC-News), how much novel signal can cultural fine-tuning provide? Prior work ([2] [3] [4] [5]) demonstrates that even modest, domain-specific fine-tuning can induce significant representational drift, overwriting pretraining attractors in both activation geometry and generation behavior. Recent studies ([6] [7] [8]) further show that targeted preference and instruction tuning reshape internal manifolds—especially in later layers ($\ell \ge 20$)—embedding new epistemic alignments and latent biases. Our latent geometry diagnostics (e.g., $\kappa_\ell, \mathcal L_\ell, |\mathbf{v}_\ell^{(c)}| $) provide direct evidence that cultural fine-tuning imprints distinctive, heritable signatures—what we term the model’s neural DNA (nDNA).
Why Cultural nDNA Matters.
By analyzing these eight culturally fine-tuned models, we reveal how fine-tuning on regionally grounded corpora leads to measurable divergence in latent geometry. Our diagnostics uncover zones of increased spectral curvature (latent manifold bending), thermodynamic length (epistemic effort), and belief vector field intensity (cultural directional pressure). This latent genomic structure offers a geometric fingerprint of cultural inheritance–demonstrating how models absorb, reframe, and propagate culturally specific epistemic priors even when built upon shared architectural foundations. Collectively, this experimental design enables a rigorous examination of how language models become vessels of culture–not just in their outputs, but deep within their hidden representations.
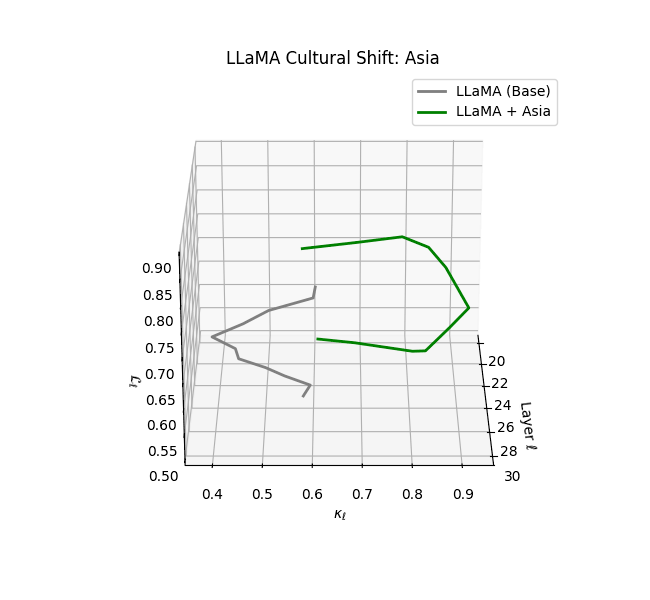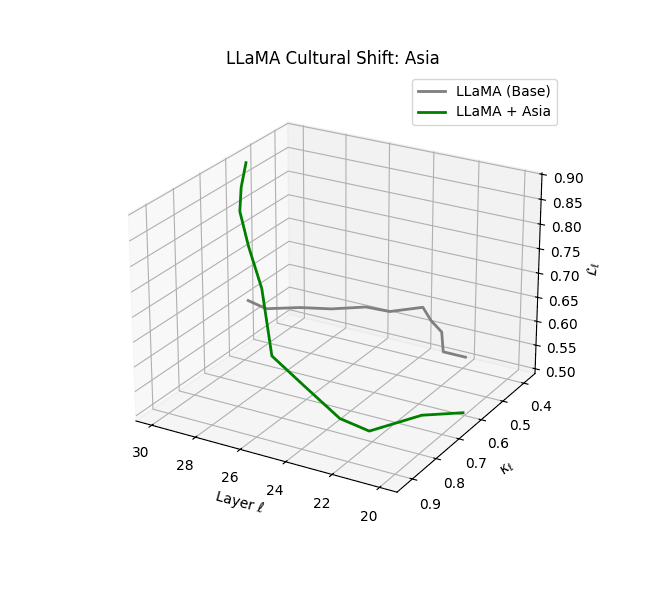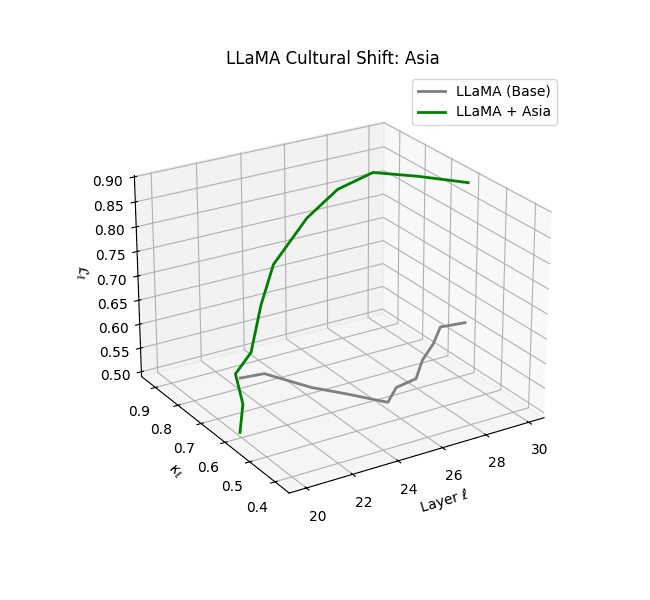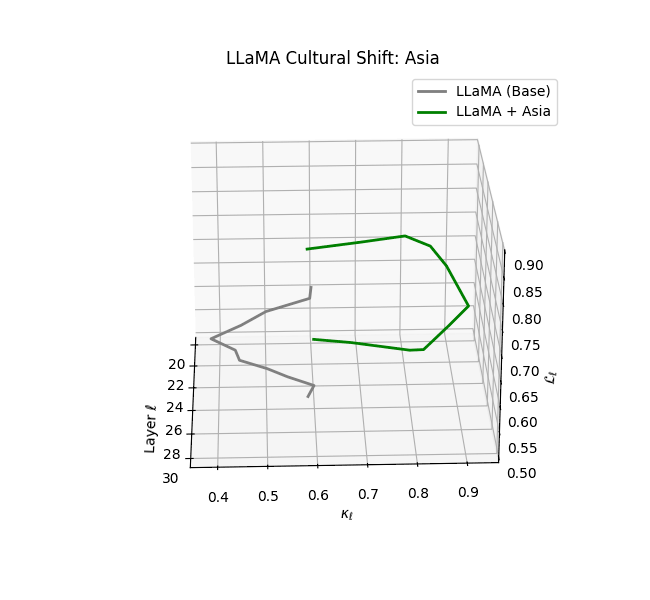
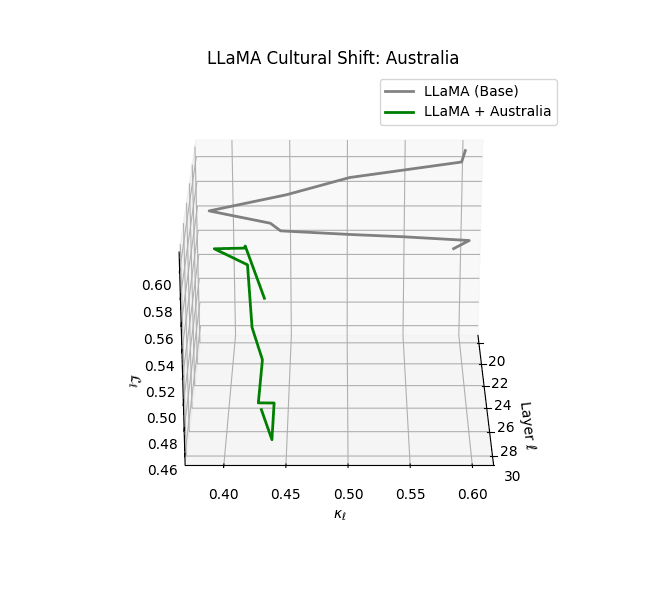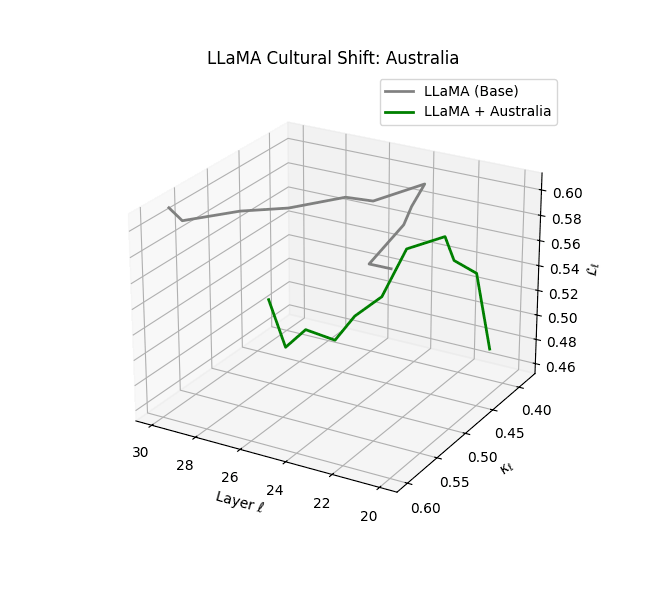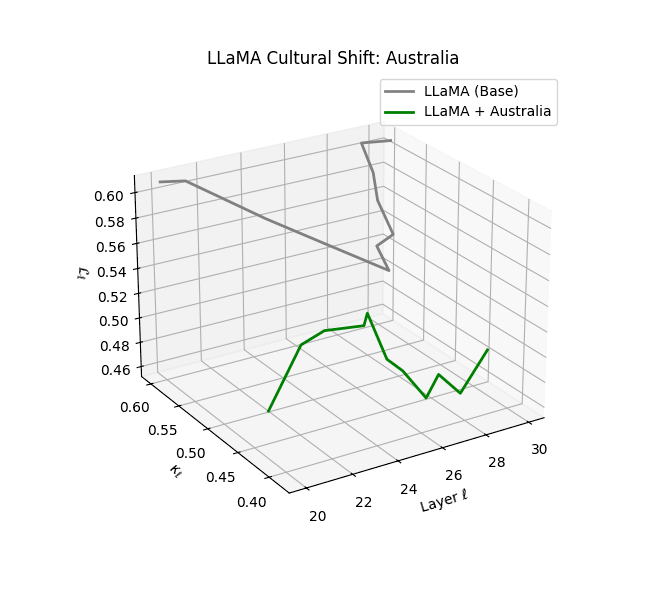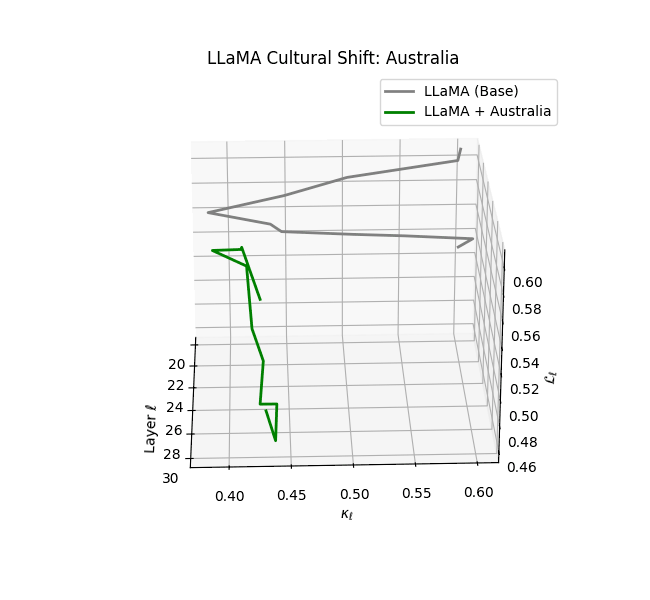
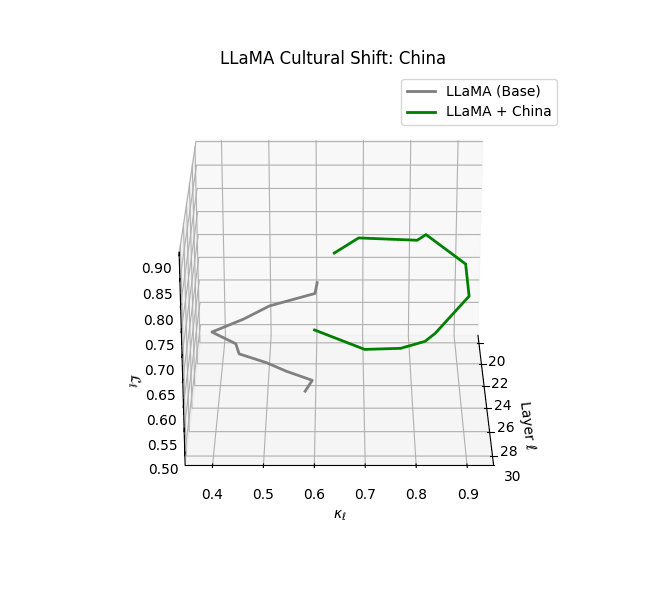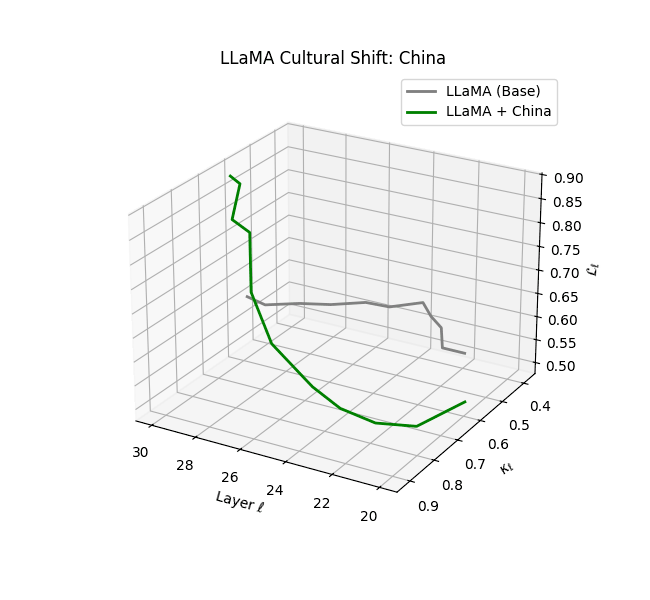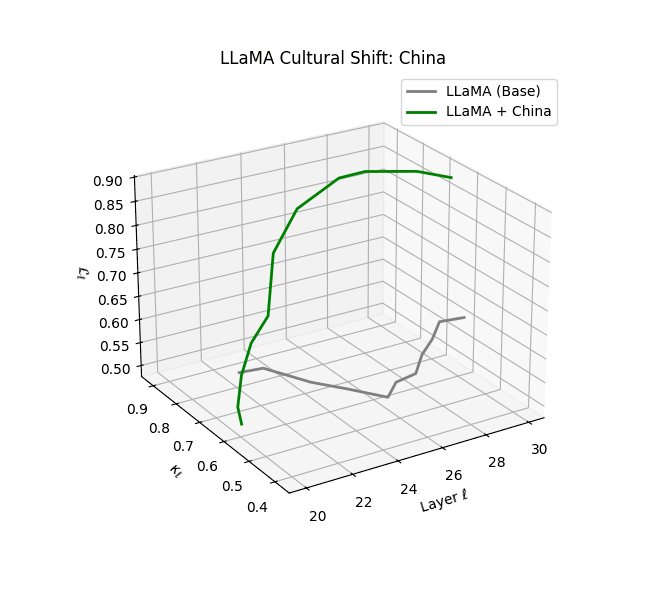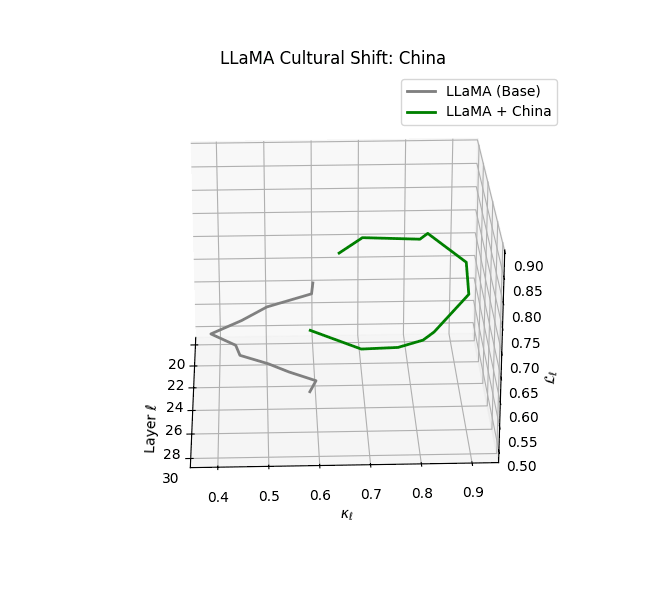
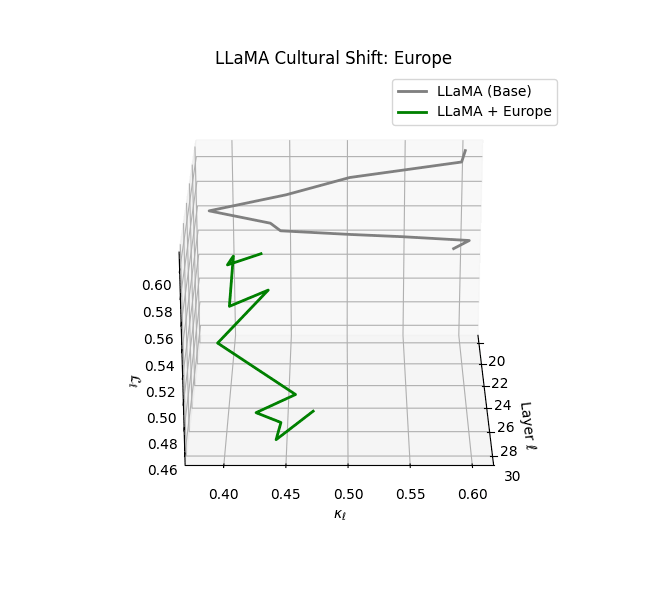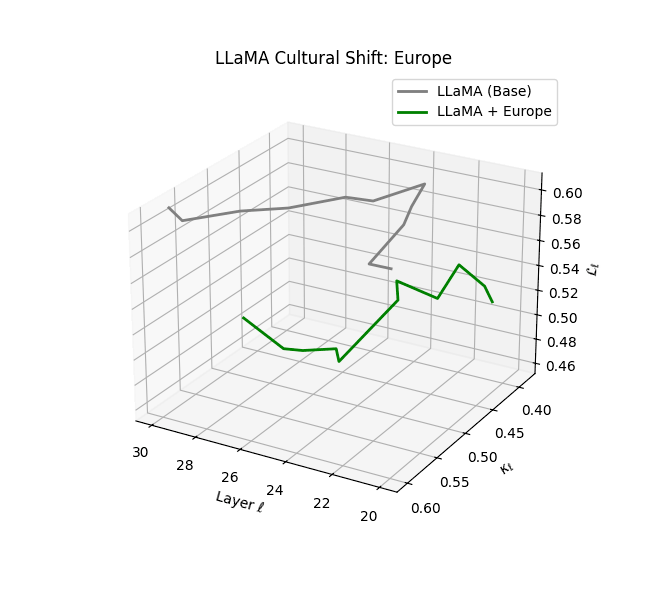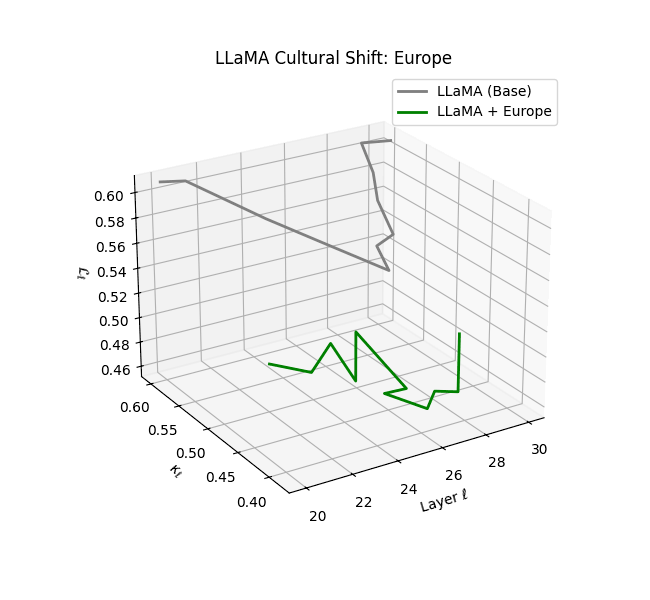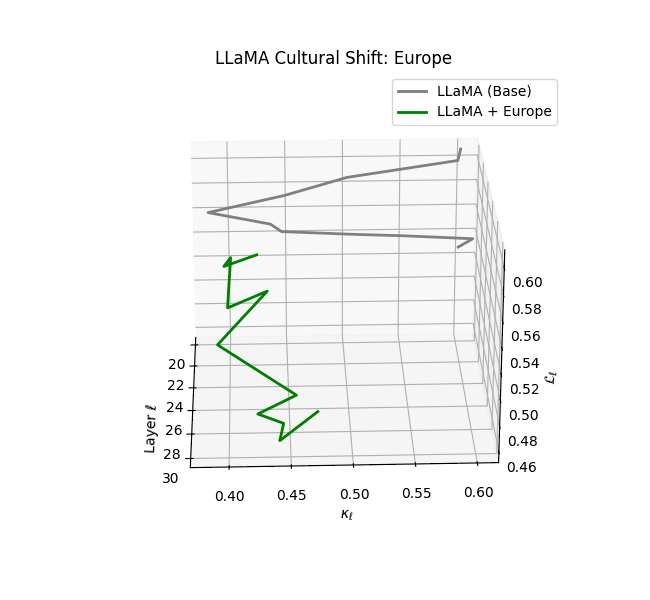
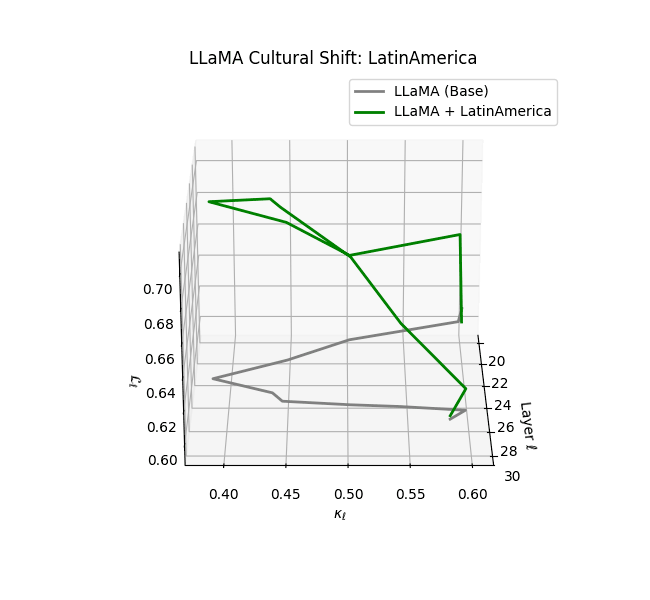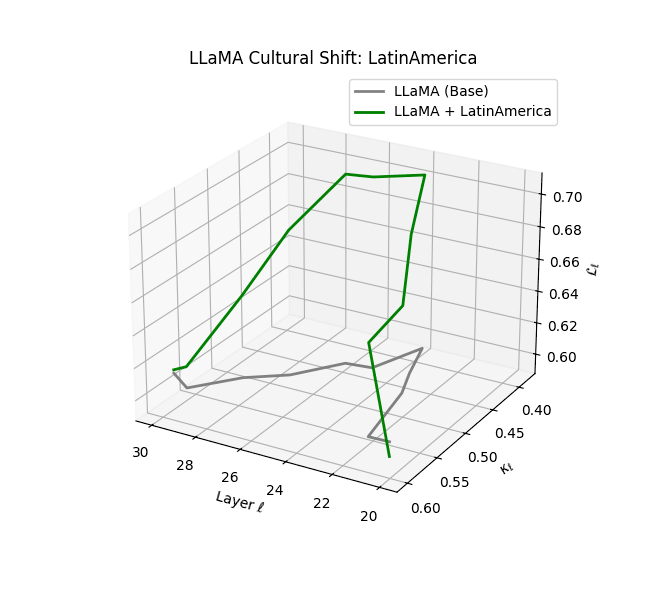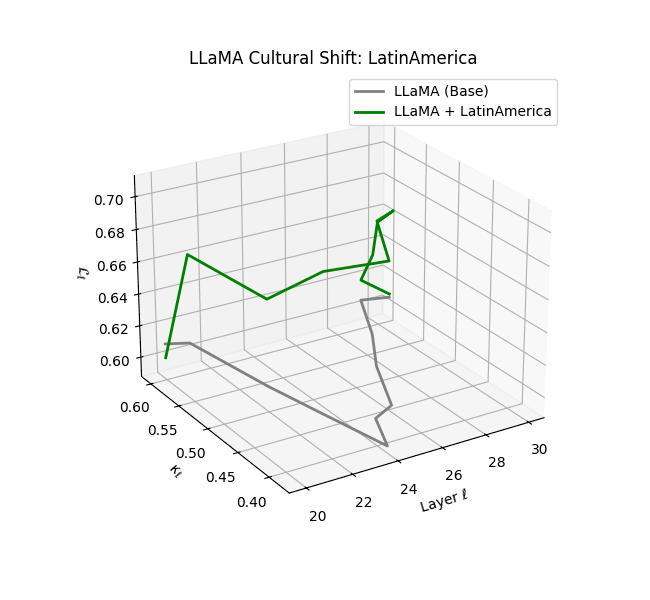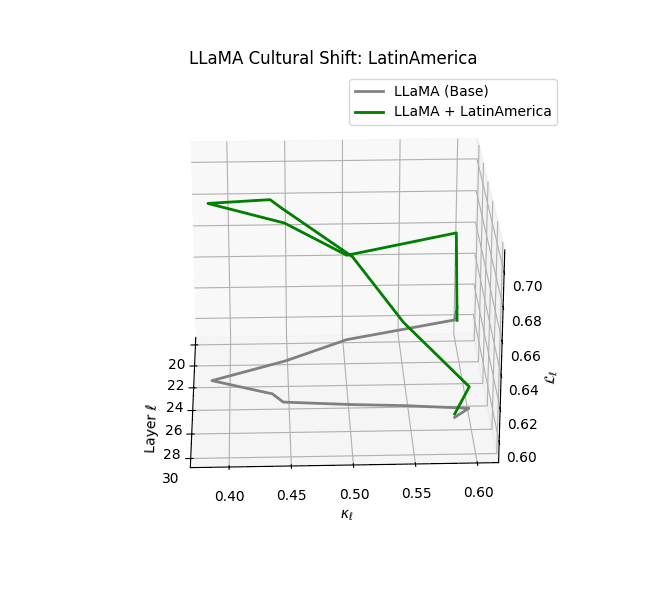
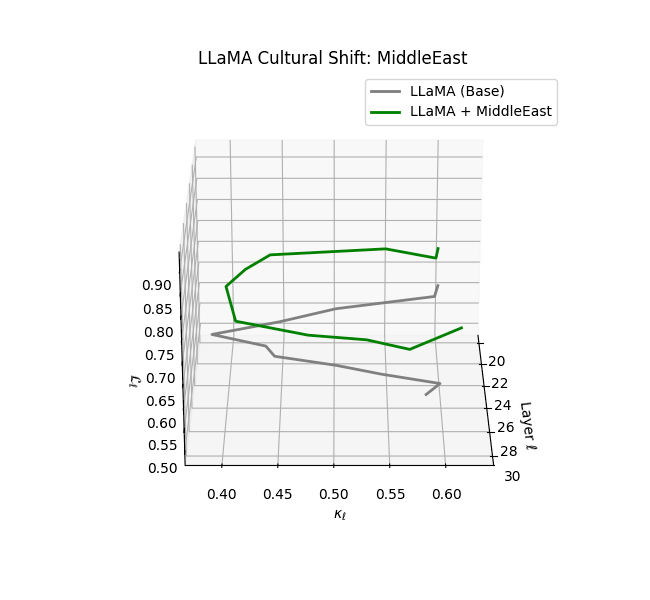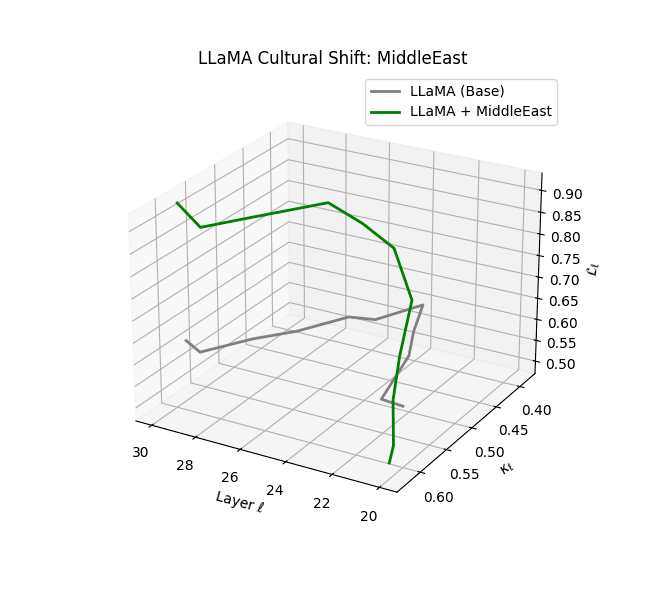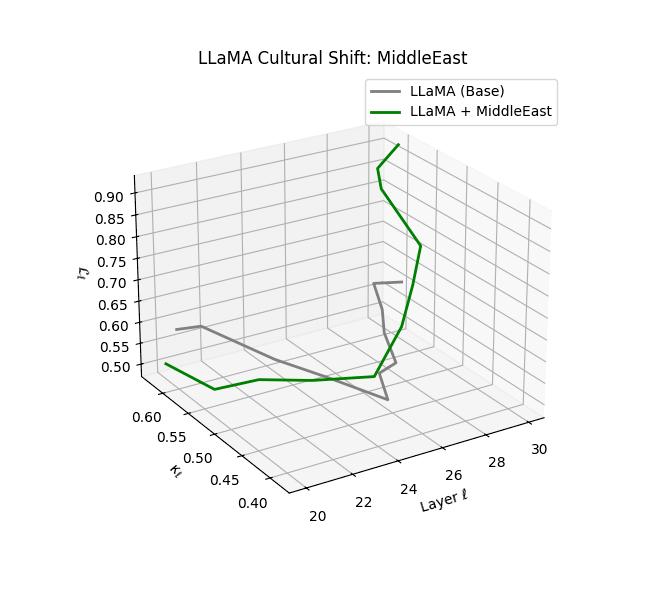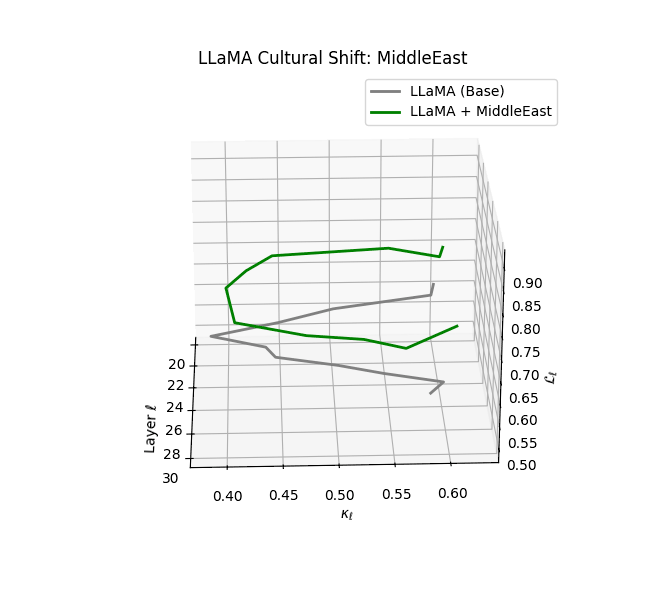
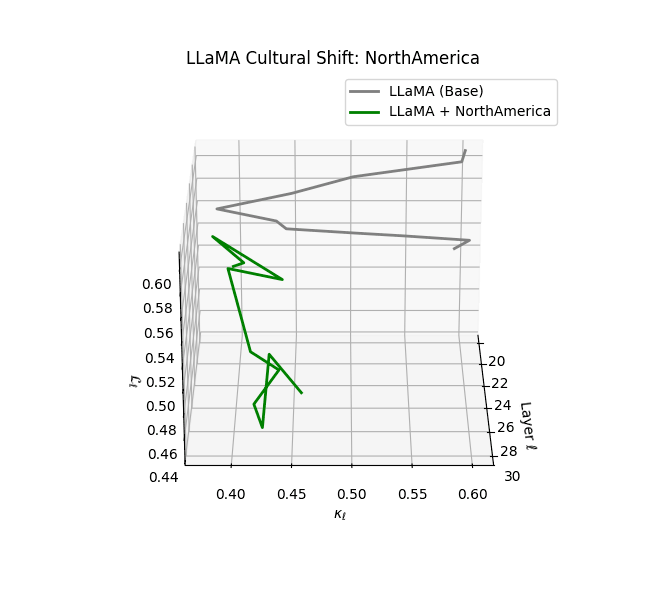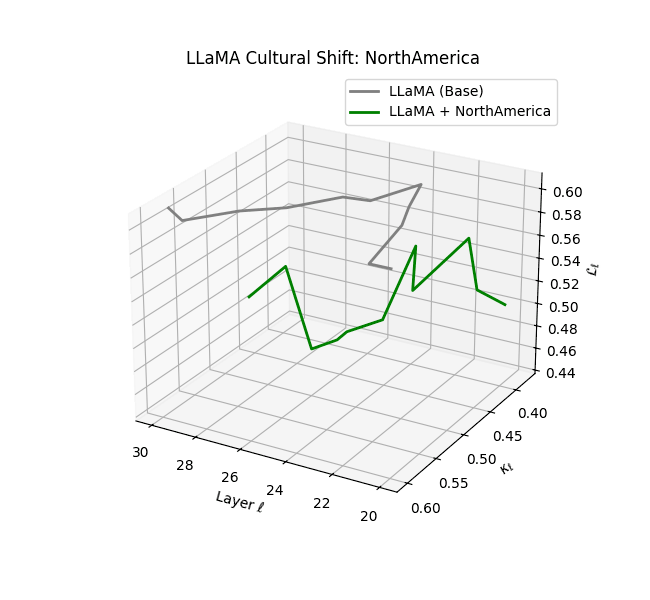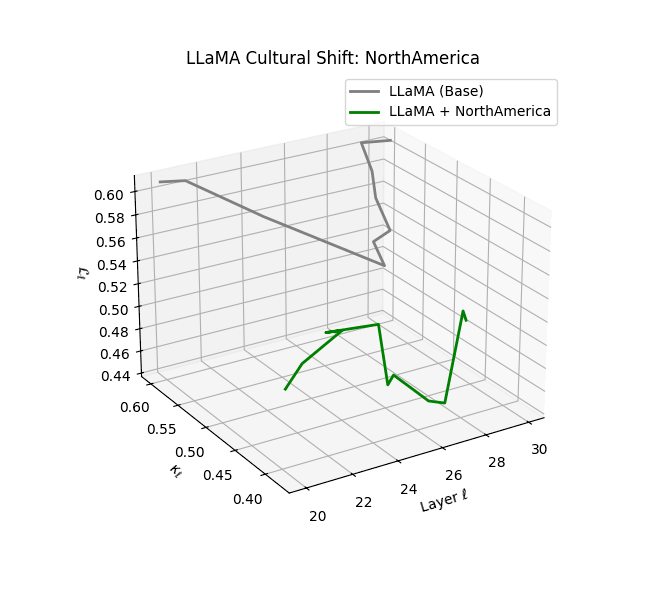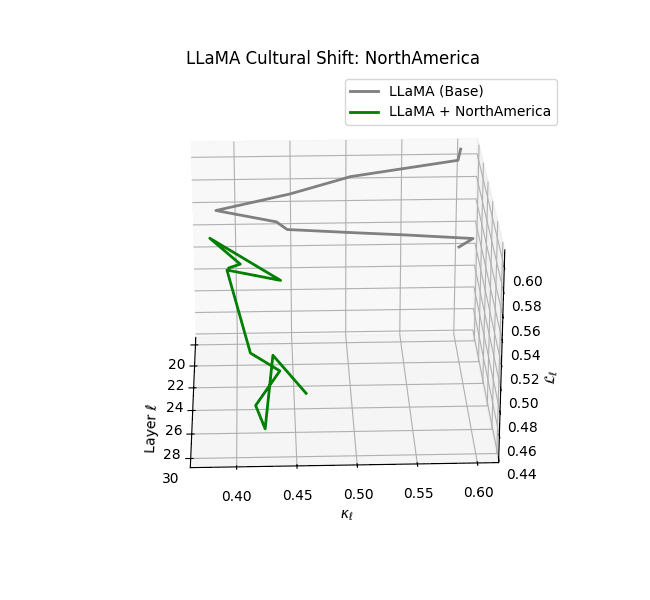
Cultural nDNAs: A Leap in Latent Genomic Understanding of LLMs
The discovery of cultural nDNA trajectories represents a conceptual leap in our ability to interpret the inner structure of LLMs. Just as the celebrated king-queen analogy in Word2Vec [9] revealed linear semantic regularities in word embeddings through \(\texttt{king} - \texttt{man} + \texttt{woman} \approx \texttt{queen}\) where this equation unveiled linear semantics at the token level, cultural nDNA exposes the differential geometry of belief systems—mapping how fine-tuning on region-specific corpora non-uniformly sculpts spectral curvature ($\kappa_\ell$), thermodynamic length ($\mathcal L_\ell$), and directional belief force ($|\mathbf v_\ell^{(c)}|$).
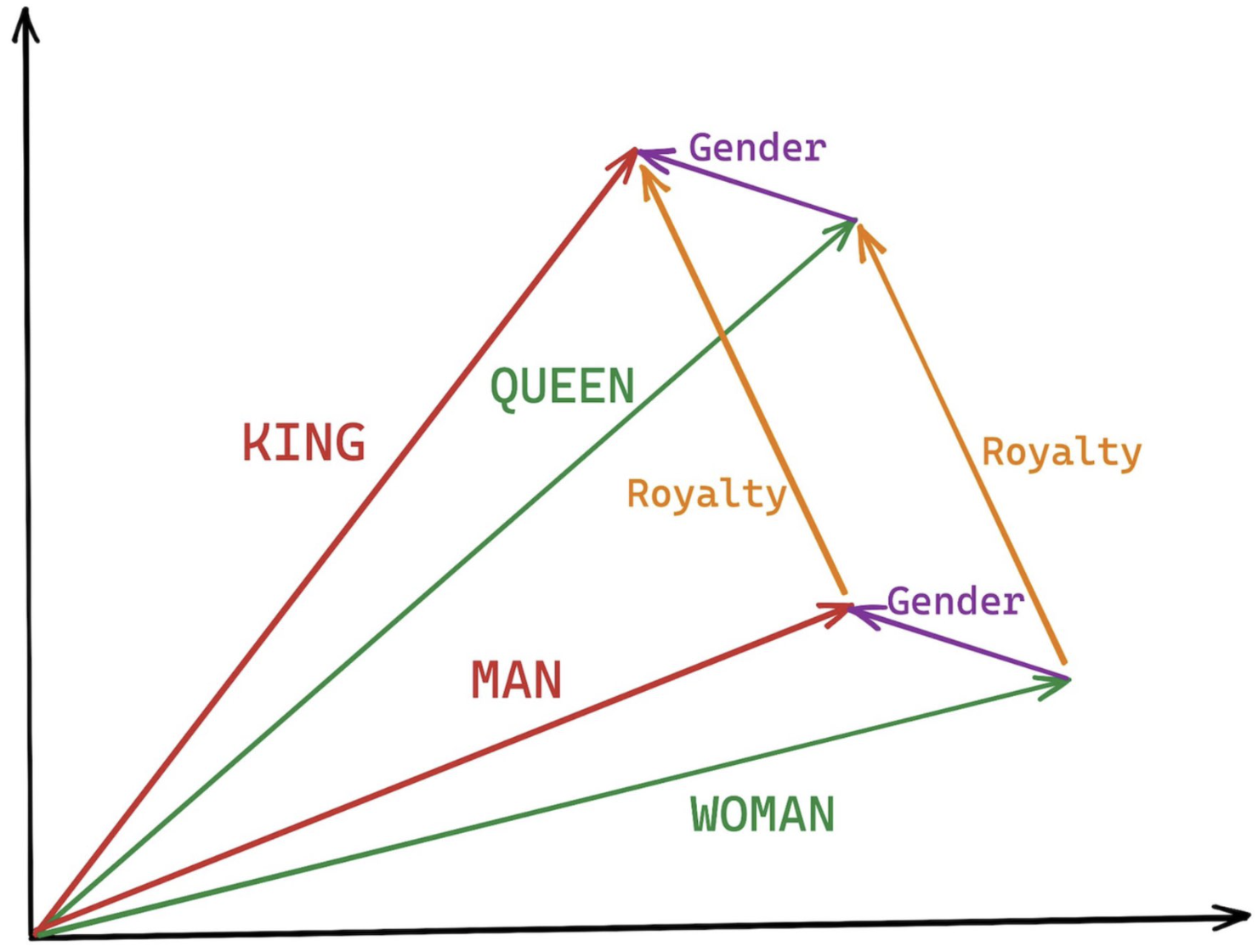
Figure 2: Word2Vec Semantic Analogy: The King-Queen Vector Geometry. This illustration depicts the iconic linear semantic regularity uncovered by Word2Vec embeddings[9], where $\texttt{king} - \texttt{man} + \texttt{woman} \approx \texttt{queen}$. The diagram visualizes how vector differences capture conceptual dimensions such as gender (purple arrows) and royalty (orange arrows), enabling algebraic reasoning in embedding space. This breakthrough marked a foundational insight in distributed semantics, inspiring later work on latent geometry in large language models.
Our analysis reveals family-level clustering and divergence:
- Western-aligned variants (Europe, North America, Australia) exhibit modest latent deformation, with $\kappa_\ell$ in $[0.045, 0.055]$ and $\mathcal{L}_\ell$ in $[0.85, 0.95]$. Their trajectories stay near the base LLaMA geometry, mirroring Western-centric pretraining bias ([10][11][12][13]).
- Non-Western models (Africa, Asia, China) show pronounced reconfiguration, with $\kappa_\ell > 0.070$ and $\mathcal{L}_\ell > 1.10$ in upper decoder layers ($\ell \geq 25$), consistent with cultural calibration and bias mitigation efforts ([15][5][6]).
- Middle Eastern and Latin American variants present localized latent oscillations ($\kappa_\ell$ fluctuating $0.050$–$0.065$, $\mathcal{L}_\ell$ peaking near $1.10$), illustrating the partial cultural rewriting phenomenon ([2][3][4]).
Beyond Surface Fairness: Latent Anatomy
These nDNA trajectories align with calls to audit foundation models not only at the output level but also in their internal representations([16][17]). nDNA is a semantic fingerprint, enabling latent audits of ideological absorption and bias inheritance ([17][18][13]).

Cultural nDNA as a Tool for Inclusive AI
This geometric fingerprinting illuminates the WEIRD bias (Western, Educated, Industrialized, Rich, Democratic) in foundation model pretraining ([13][19]) , and its mitigation via cultural fine-tuning ([14][6]). Western models cluster near pretraining attractors; non-Western models incur latent cost to encode distinct priors, supporting concerns of representational inequality [21][20].
From Vector Algebra to Latent Geometry
Where vector arithmetic revealed word-level embedding regularities, nDNA geometry charts ideological inheritance across high-dimensional latent manifolds. This leap enables: i) principled comparison of culturally fine-tuned models, ii) diagnosis of latent strain and mutation zones, iii) development of culturally calibrated, equitable foundation models [ 15][18][3]. Cultural nDNA thus transcends surface output metrics—offering a mathematical, interpretable, and actionable map of neural ancestry and epistemic adaptation in modern AI.
References
- H. Touvron and Others, “Llama: Open and efficient foundation language models,” arXiv preprint arXiv:2302.13971, 2023.
- Z. Diao, A. Li, and J. Xu, “Overwriting pretraining distributions through fine-tuning,” in ICML 2024, 2024, to appear.
- W. Zhao, S. He, and Y. Gao, “Language models forget in latent space,” in NeurIPS 2023, 2023.
- W. Zhao, C. Liu, and Y. Gao, “Calibrating language models via latent geometry,” in ICLR 2023, 2023.
- X. Huang, Z. Dai, L. Zhou et al., “Replug: Retrieval-augmented black-box language models,” in ICLR 2023, 2023.
- Y. Xiang, Z. Zhao, X. Tan et al., “Cultural calibration of large language models,” in Proceedings of ACL 2024, 2024.
- M. S. Rafi et al., “Discovering and mitigating cultural biases in llms through synthetic preference tuning,” arXiv preprint arXiv:2311.07744, 2023.
- L. Ouyang, J. Wu, X. Jiang, D. Almeida, C. Wainwright, P. Mishkin, C. Zhang, S. Agarwal, A. Slama, C. Ray et al., “Training language models to follow instructions with human feedback,” Advances in Neural Information Processing Systems, vol. 35, pp. 27 730–27 744, 2022.
- T. Mikolov, K. Chen, G. Corrado, and J. Dean, “Efficient estimation of wordrepresentations in vector space,” in Proc. of ICLR (Workshop), 2013. [Online]. Available: https://arxiv.org/abs/1301.3781
- S. Mukherjee, R. Dossani, and A. H. Awadallah, “Globalizing bert: A comprehensive multilingual evaluation,” arXiv preprint arXiv:2008.00364, 2020.
- E. Sheng, K.-W. Chang, P. Natarajan, and N. Peng, “The woman worked as a babysitter: On biases in language generation,” in Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing (EMNLP) and the 9th International Joint Conference on Natural Language Processing (IJCNLP). Association for Computational Linguistics, 2019, pp. 3407–3412. [Online]. Available: https://aclanthology.org/D19-1340
- E. Sang, B. Van Durme, and R. Cotterell, “Evaluating the cross-linguistic fairness of nlp systems,” in Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics (NAACL), 2022, pp. 3334–3349.
- R. Mihalcea, O. Ignat, L. Bai, A. Borah, L. Chiruzzo, Z. Jin, C. Kwizera, J. Nwatu,S. Poria, and T. Solorio, “Why ai is weird and shouldnt be this way: Towards ai for everyone, with everyone, by everyone,” Proceedings of the AAAI Conference on Artificial Intelligence, vol. 39, no. 27, pp. 28 657–28 670, 2025. [Online]. Available: https://ojs.aaai.org/index.php/AAAI/article/view/35092
- B. Peng, L. Wang, and X. Li, “Culturally aligned language modeling: Methods and benchmarks,” ACL, 2024.
- D. Ganguli et al., “Reducing sycophancy in large language models via self-distillation,” arXiv preprint arXiv:2305.17493, 2023.
- R. Bommasani et al., “Foundation models: Past, present, and future,” arXiv preprint arXiv:2309.00616, 2023.
- Z. Wang, Y. Xu, J. Yan, Y. Lin, and J. Zhou, “Cultural bias in large language models: A survey,” arXiv preprint arXiv:2311.05691, 2023.
- E. Laurens et al., “The ethics of alignment: Towards culturally inclusive foundation models,” in Proceedings of the AAAI Conference on Artificial Intelligence, 2024.
- J. Henrich, The Weirdest People in the World. Farrar, Straus and Giroux, 2010.
- S. L. Blodgett, S. Barocas, H. Daumé III, and H. Wallach, “Language (technology) is power: A critical survey of bias in nlp,” Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pp. 5454–5476, 2020.
- E. Sheng, Z. Zhang, K.-W. Chang, and P. Natarajan, “Revealing the critical role of pre-training data in language model bias,” in Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing (EMNLP). Association for Computational Linguistics, 2021, pp. 864–873. [Online]. Available: https://aclanthology.org/2021.emnlp-main.65.